 dauert")
Text Mining wird teilweise auch als Text Data Mining bezeichnet, was die Beziehung zum allgemein geläufigeren Begriff Data Mining verdeutlicht. Der Begriff Data Mining setzt sich aus den beiden Komponenten Data (Daten) und Mining (graben, abbauen) zusammen. Mithilfe von Data Mining sollen bestehende Hypothesen überprüft und neue, d.h. bisher verborgene Zusammenhänge in großen Datensätzen erkannt werden.
Vor diesem Hintergrund repräsentiert Data Mining einen Schritt innerhalb einer gesamten Prozesskette, zu der auch die Auswahl, Erfassung, Speicherung, Vorverarbeitung, Transformation und Präsentation der Daten respektive der Analyseergebnisse gehören. Im allgemeinen Sprachgebrauch wird der Begriff Data Mining der Einfachheit halber auf den gesamten Prozess der Knowledge Discovery (Wissensentdeckung in Datenbanken) übertragen. Der bekannteste Knowledge-Discovery-Prozess ist der sogenannte CRISP-DM. Das Akronym steht für CRoss-Industry Standard Process for Data Mining.

Für jeden Datentyp gibt es entsprechende Data-Mining-Verfahren, und so auch für den Datentyp Text. Vor dem Hintergrund des Data Mining bezieht sich der Begriff Text Mining auf die Analyse von Textdaten unterschiedlicher Herkunft und Struktur. Analog zu der o.g. allgemeinen Zielbeschreibung des Data Mining geht es auch beim Text Mining um die Verifikation von Hypothesen und die automatisierte Generation neuen Wissens.
Wie funktioniert Text Mining?
Entgegen numerischen oder alpha-numerischen Daten weisen Textdaten nur sehr selten eine eindeutige und einheitliche Struktur auf, liegen also i.d.R. nur schwach, halb- oder komplett unstrukturiert vor. Insbesondere die der Textform eigenen semantischen, syntaktischen oder typographischen Merkmale erschweren die Analyse. Entsprechend kommt der Vorverarbeitung der Textdaten eine wichtige Rolle zu. Mit Hilfe von NLP (Natural Language Processing) sollen Strukturen in der menschlichen Sprache erkannt und soweit verarbeitet bzw. abstrahiert werden, dass der Computer eine Analyse durchführen kann.
Das Konzept hinter NLP lässt sich bis in die 1960er Jahre zurückverfolgen. Der Begriff NLP (im deutschsprachigen Raum teilweise auch als Computerlinguistik bezeichnet) bezieht sich auf die computergestützte Verarbeitung von Informationen in natürlicher Sprache, wobei es unerheblich ist, ob es sich dabei um gesprochene oder geschriebene Sprache handelt. Als Schnittstelle zwischen Sprachwissenschaft und Informatik und als Teilbereich der Künstlichen Intelligenz liefert NLP eine Antwort auf die Frage, wie natürliche Sprache in ein maschinenlesbares Format überführt und entsprechend analysiert werden kann. Insbesondere die Übersetzung natürlicher gesprochener Sprache in analysierbare Datenpunkte gewinnt zunehmend auch in unserem privaten Alltag an Bedeutung – Sei es im Zuge der Sprachsteuerung via „Alexa“, „Ok Google“ oder „Hey Siri“ oder während der Kommunikation mit Chatbots.

Eine konkrete Methode der Vorverarbeitung ist das Part-of-Speech-Tagging (POS-Tagging). Mit Hilfe von POS-Tagging wird jedem Token (Wort oder Satzzeichen innerhalb eines Textdokuments) eine grammatische Kategorie (Part-of-Speech; POS-Tag) attributiert. Der Detailgrad des zugewiesenen POS-Tags variiert dabei in Anlehnung an das verwendete Verfahren. Sogenannte Fine-Grained-Tagger bieten dem Nutzer neben der Information über die grammatische Kategorie auch Informationen hinsichtlich der Flexion (Person, Numerus, Tempus, Modus, Genus, Kasus, Stärke- und Komparationsstufe). Die dabei zur Verfügung stehenden POS-Tags stammen beim überwachten Lernen aus einem vordefinierten Tagset. Im deutschen Sprachraum wird dafür üblicherweise das Stuttgart-Tübingen-Tagset (STTS) verwendet. Beim unüberwachten Lernen entsteht das Tagset durch die Anwendung stochastischer Verfahren. Mithilfe von POS-Tagging können für die nachfolgenden Analysen spezifische Tags ausgewählt oder aus dem Datensatz entfernt werden. POS-Tagging unterstützt also dabei, das Rauschen und die Heterogenität innerhalb des Textdatensatzes zu reduzieren. Als besonders aussagekräftig und wertvoll erweisen sich z.B. POS-Tags, die der Gruppe der Content Words zugeordnet werden können (Substantive, Verben, Adjektive, Adverben). Im Gegensatz dazu liefern POS-Tags der Gruppe Function Words (u.a. Artikel, Pronomen, Präpositionen) i.d.R. keinen Mehrwert hinsichtlich der Analyse, wobei es natürlich immer auf den jeweils individuellen Kontext ankommt.

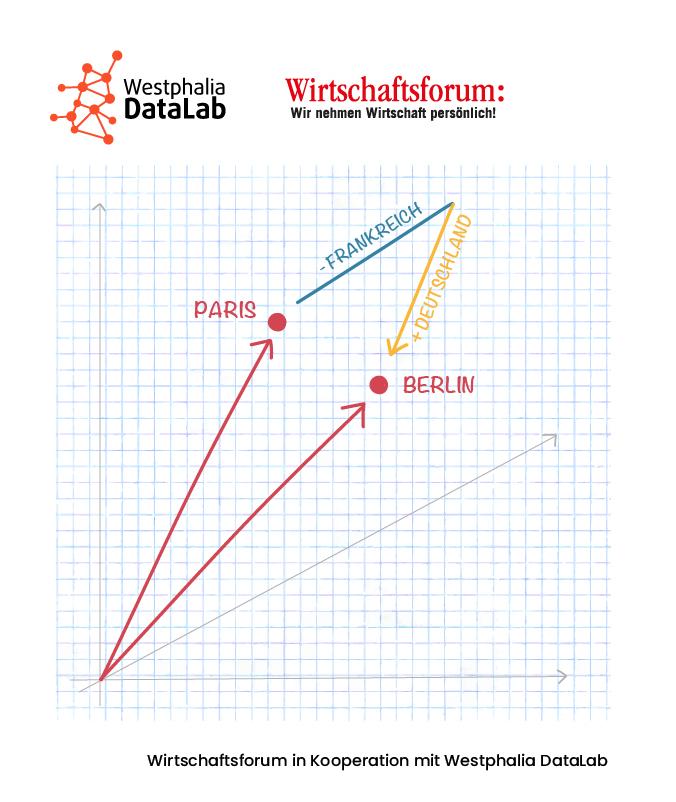
Die Identifikation von Synonymen und Word Embeddings mit Hilfe von Word2Vec ist einer der bekanntesten Verfahren innerhalb des NLP. Wie der Begriff es vermuten lässt, werden basierend auf dem Word2Vec-Ansatz Worte als Vektoren in einem mehrdimensionalen Vektorraum repräsentiert. Dank der Vektorform können nun auch mit Worten mathematische Operationen durchgeführt werden. So lassen sich z.B. Distanzen zwischen zwei oder mehr Worten berechnen und entsprechende Rückschlüsse auf deren semantische bzw. kontextuelle Ähnlichkeit ziehen. In der Gestalt eines Vektors kommt jedem Wort ein fester Platz im Vektorraum zu, wobei Vektoren von ähnlichen Worten nah beieinander liegen. Die Distanz zwischen den Worten kann mittels verschiedener mathematischer Basisverfahren ermittelt werden, z.B. der Euklidischen Distanz, die den reinen Abstand ermittelt oder der Kosinus Distanz, mit der eine Ähnlichkeit zwischen -1 und 1 berechnet werden kann. Auf dem Word2Vec Ansatz basieren u.a. Anwendungen, die auf der Verarbeitung gesprochener Sprache basieren. Dank Word2Vec führen sowohl „Siri, spiel Musik“ als auch „Siri, mach die Musik an“ oder „Siri, spiel ein Lied“ zum gleichen Ziel.
Jedes Wort lässt sich in einen Wortvektor umwandeln, so dass damit gerechnet werden kann. Es gibt vortrainierte Wortvektoren in vielen gängigen Sprachen, die üblicherweise etwa 300 Dimensionen, also Vektoren mit 300 Zeilen enthalten. Um diese zu erstellen, haben verschiedene Anbieter von Wortvektor-Sammlungen z.B. auf der nationalen Wikipedia-Seite, den Nachrichten oder anderen im Internet verfügbaren Texten Wörter analysiert. So konnte herausgefunden werden, welche Ausprägungen welches Wort hat und auch andere Anwender können nun damit arbeiten:

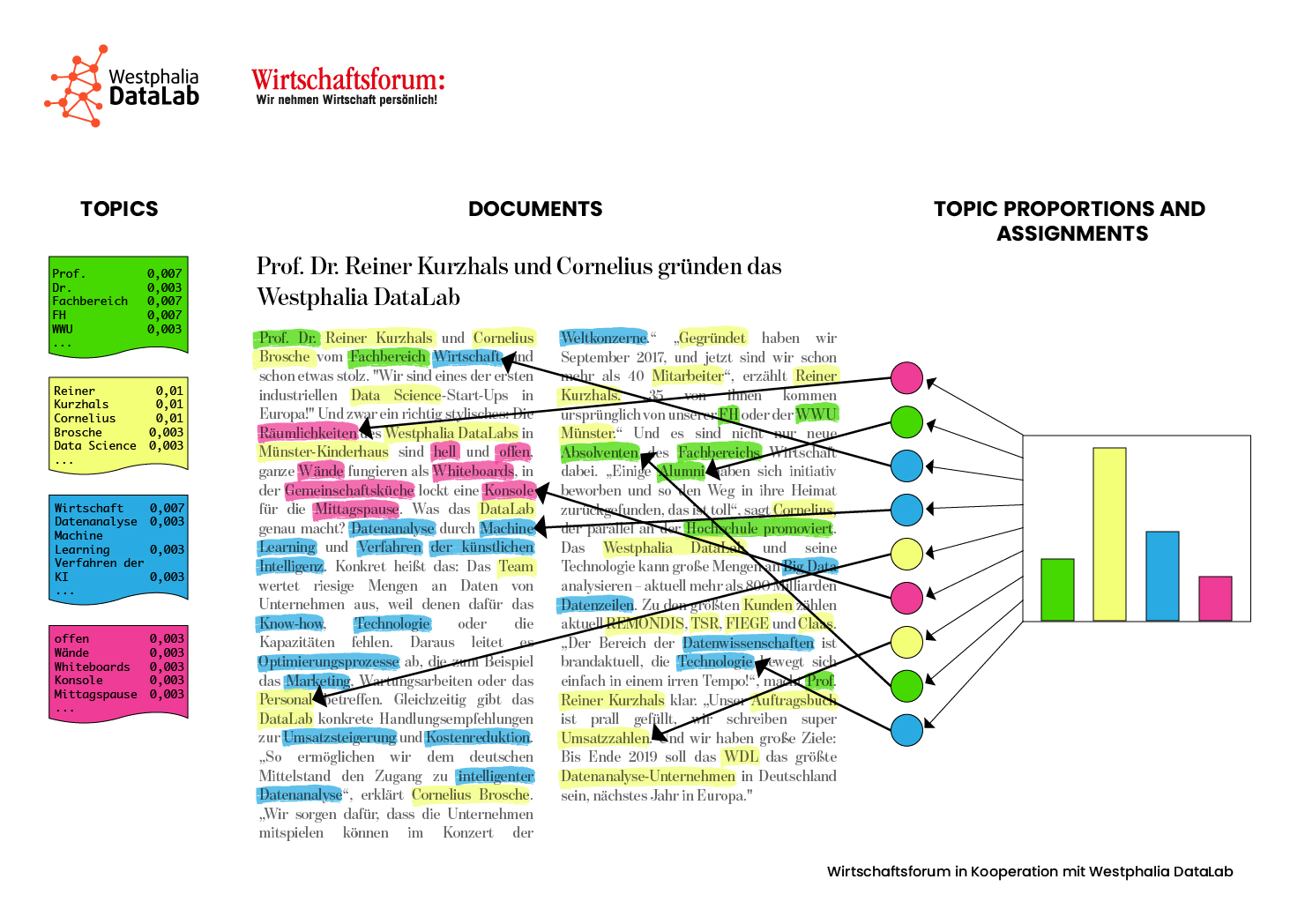
Die Zuordnung verschiedener Textdokumente zu inhaltlichen Gruppen bzw. Oberthemen (Topics) bezeichnet man als Topic Modelling. Die Zuordnung basiert auf einem statistischen Modell, das semantisch ähnliche Worte, d.h. Worte, die in ähnlichen Kontexten eingebettet sind, über eine Vielzahl an Textdokumenten identifiziert. Die sich daraus ergebenden Oberthemen bestehen dann aus einer Menge ähnlicher Worte. Die Oberthemen können vorher bekannt sein bzw. der Vorahnung entsprechen oder neue, bislang verborgene Zusammenhänge offensichtlich machen. Topic Modelling erlaubt es also, riesige Mengen an unstrukturierten Texten zu organisieren. Um Wörter zu gruppieren, mit denen Textdokumente weiterverarbeitet werden können, ist z.B. mit dem Latent Dirichlet allocation-Algorithmus (LDA), einem Topic Modelling-Algorithmus möglich. Bei der latenten Zuordnung nach dem deutschen Mathematiker Dirichlet wird ein Wahrscheinlichkeitsmodell für Wörter erstellt. Im LDA-Prozess wird die Anzahl der Themen durch den Nutzer festgelegt. Jedes Dokument enthält mehrere Themen, die unterschiedlich stark ausgeprägt sind. Jedes Wort wird einem Thema zugeordnet. Mit Hilfe des nicht überwachten Lernalgorithmus LDA wird versucht, Beobachtungen als Mischung unterschiedlicher Kategorien zu beschreiben.
")
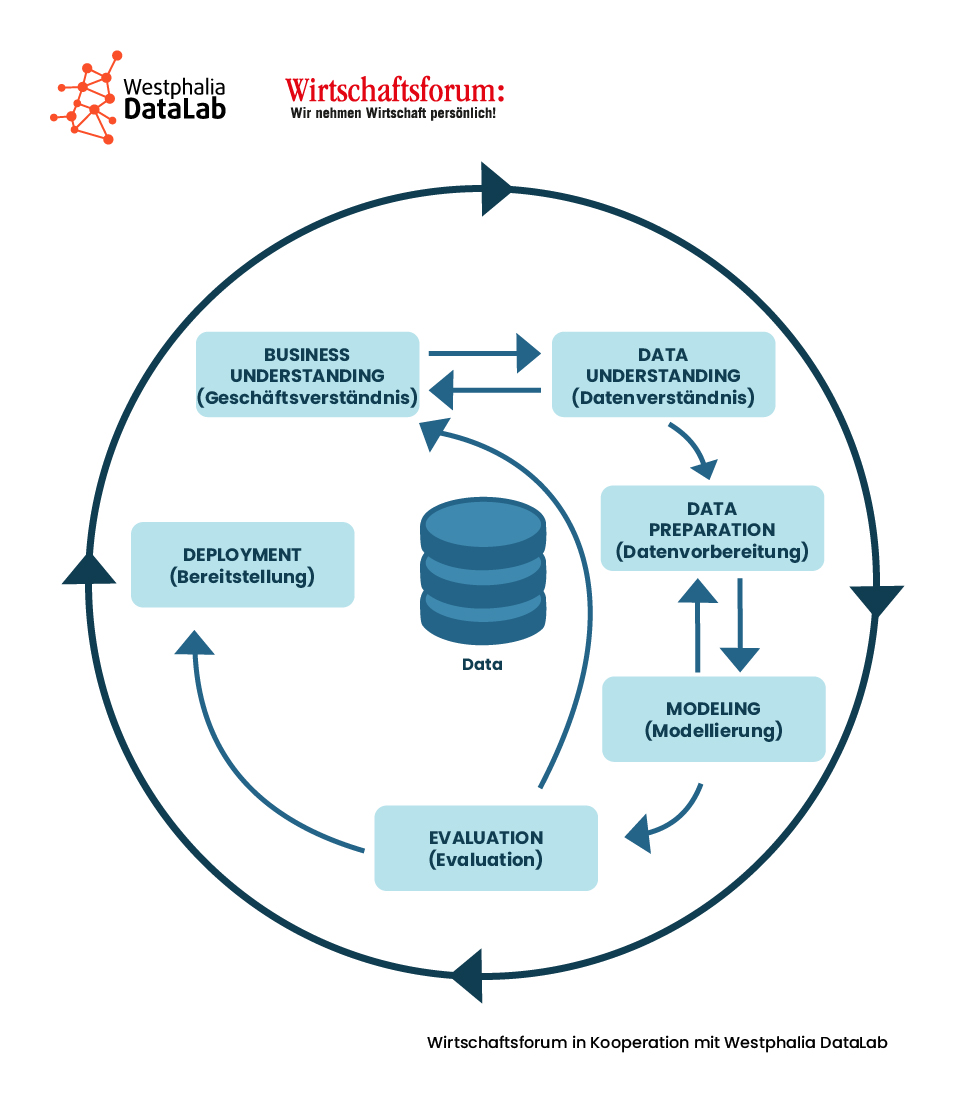
Wie läuft ein Text-Mining-Projekt ab?
Analog zu allgemeinen Data-Mining-Projekten kann auch der Ablauf eines Text-Mining-Projektes mit dem CRISP-DM-Prozess abgebildet werden:
- Business Understanding: Was möchte ich eigentlich herausfinden? Welche messbaren Ziele verfolge ich mit der Textanalyse? Welche Textdaten stehen uns zur Verfügung, welche Informationen fehlen?
- Data Understanding: Aus welcher Datenquellen beziehen wir die Textdaten? Was müssen wir über die Textdaten und deren Entstehung wissen? Gibt es relevante Metadaten, die es zu beachten gilt?
- Data Preparation: Reicht die Datenbasis für eine Analyse aus oder müssen (z.B. mit Crawlern) weitere Textdaten hinzugefügt werden? In welcher Struktur liegen die Textdaten vor? Welche Vorverarbeitungsschritte sind nötig, um das definierte Ziel zu erreichen?
- Modelling: Welches ist das passende Modell? Welches sind die erforderlichen Parameter?
- Evaluation: Wie kann die Ergebnisqualität gemessen werden? Passen die Ergebnisse zu der Zielsetzung? Wie lassen sich die Ergebnisse visuell aufbereiten?
- Prototyping & Deployment: Wie kann die Textanalyse vollständig automatisiert und in den Regelbetrieb überführt werden? Welche gestalterischen und nutzerspezifischen Parameter gibt es zu beachten?
Welche Probleme gibt es beim Text Mining?
Die Qualität eines Text-Mining-Ergebnisses hängt in großen Teilen von den zur Verfügung stehenden Daten ab. Je größer die Menge und je präziser die Vorverarbeitung, desto besser ist das Ergebnis. Doch die Sammlung und Vervielfältigung von Textdaten ist nicht ganz unproblematisch. Die bestehenden rechtlichen Rahmenbedingungen legen dem Text Mining oft Steine in den Weg. So haben beispielsweise Einzelpersonen Zugriff auf Textdokumente und dürfen diese ohne Einschränkung lesen und verarbeiten. Findet die Verarbeitung automatisiert statt und werden in Zuge dessen die Textdaten an verschiedenen Personen versendet, müssen i.d.R. Kopien der Inhalte erstellt werden. Das Urheberrecht schützt jedoch das Vervielfältigungsrecht, was an dieser Stelle bereits zu Problemen führen kann.
Da die meisten Texte ein Individuum i.S. einer natürlichen Person als Urheber haben, erfordert der Umgang mit Textdaten ein besonderes Maß an Vorsicht. Die persönlichen Daten, die in Text-Mining-Analysen einfließen, müssen pseudo- oder anonymisiert und vor Diebstahl und Missbrauch geschützt werden. Die gesetzlichen Bestimmungen der Datenschutzgrundverordnung müssen oberste Priorität haben, was ein Text-Mining-Projekt teilweise mit zusätzlichen Anforderungen und sich daraus ergebenden Arbeitsschritten entschleunigen kann.
Eine weitere Herausforderung ist die Verteilung von Textdaten auf viele verschiedene Plattformen mit unterschiedlichen Schnittstellen und in uneinheitlicher Formatierung. Das betrifft insbesondere die Analyse von Kundenfeedback. Kunden äußern sich via E-Mail, Telefon, Chat oder in Social Media. Um ein ganzheitliches Abbild der Kundenperspektive zu gewährleisten, müssen die verschiedenen Datenquellen integriert und die unterschiedlichen Textstrukturen vereinheitlicht werden. Nicht selten liegen Textdokumente auch im PDF-Format vor. Hier ist eine Informationsextraktion zwar möglich, aber deutlich aufwändiger, als es bei strukturierten Formaten wie HTML oder XML der Fall ist.
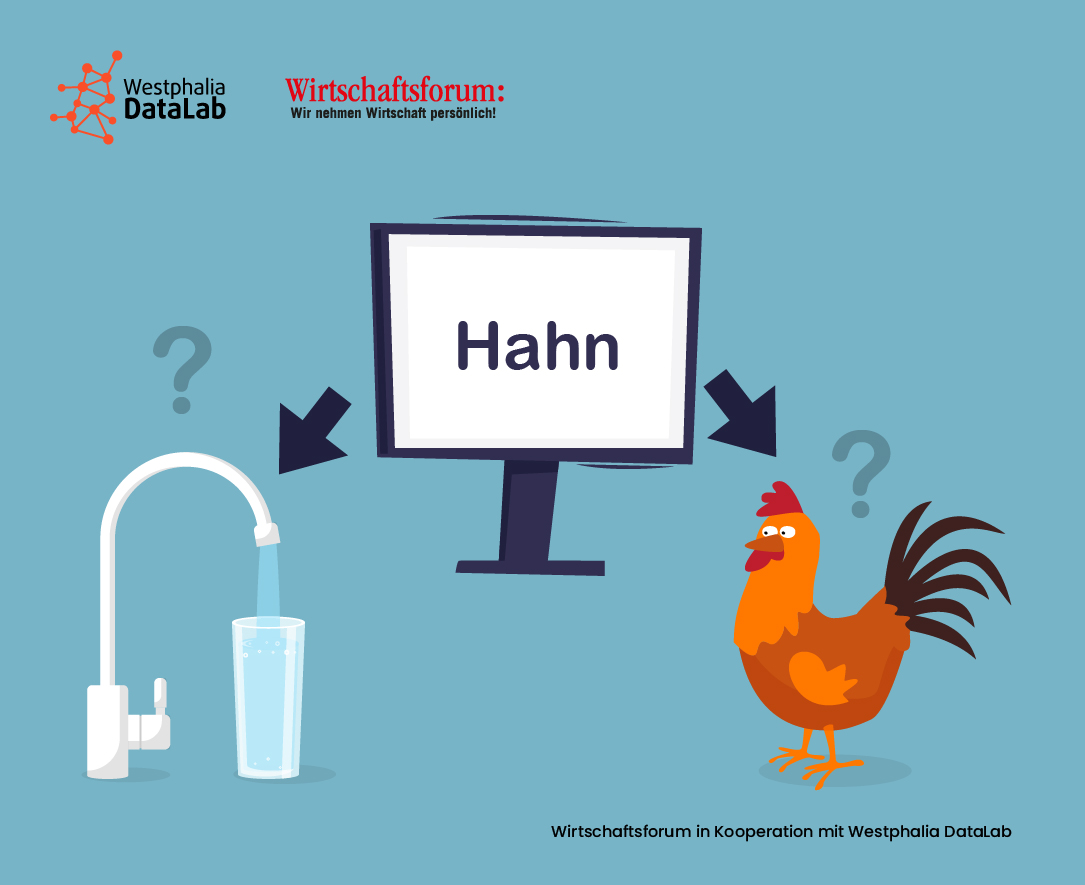
Auch wenn ein großer Teil der Analyse mittlerweile automatisiert erfolgt, ist die Expertise der Mitarbeiter, fachlich und vor allem in ihrer Rolle als „Mensch mit Sprachverstand und Kommunikationskompetenz“, von großer Bedeutung. Herausforderungen bei der Verarbeitung und Analyse von Text sowie bei der Interpretation der Analyseergebnisse stellen nach wie vor die wortimmanente Ambiguität, das Vorhandensein synonymer Ausdrücke, Ironie, Sarkasmus und Metapher sowie die generelle Weiterentwicklung von Sprache und Vokabular dar. Je nach Kontext kann ein und dasselbe Wort beispielsweise unterschiedliche Bedeutungen implizieren. Ein und derselbe Sachverhalt kann auf unterschiedliche Weise und unter Zuhilfenahme verschiedener Worte ausgedrückt werden. Die lexikalische Bedeutung einer Textpassage ist dann hinfällig, wenn der Inhalt eigentlich ironisch gemeint war. Für Aktivitäten und Vorgänge werden permanent neue Wörter erfunden („gegengoogeln“), die es vorher schlichtweg nicht gab – Weil es die Aktivität nicht gab. Ähnlich herausfordernd können bei der Analyse Synonyme („Heißt die orangene Frucht nun Apfelsine oder Orange?“), Ironie (Wie ist das „Gut gemacht!“ gemeint?), Metapher („Hier steppt der Bär.“) oder Neologismus (Was ist denn „simsen“?) sein.

Welche Vorteile ergeben sich durch Text Mining für Unternehmen?
Mittlerweile verfügt jede Abteilung innerhalb eines Unternehmens über eine nicht unbeachtliche und stetig wachsende Menge an Text, sei es der Kundenservice, das Qualitätsmanagement, das Marketing oder die Rechtsabteilung. Dabei beherbergt jedes Textdokument relevante Informationen, die es zu identifizieren gilt: Worüber beschweren sich die Kunden? Was gefällt den Kunden, was nicht? Welche Themen beschäftigen die Kunden? Wer ist eigentlich mein Kunde? Die Zahl der Textdokumente, die heute in Unternehmen eingehen und verarbeitet werden müssten, nimmt kontinuierlich zu. „Müssten“, denn ungeachtet der wachsenden Textmenge und stetig optimierten Möglichkeiten der (teil-)automatisierten Textanalyse scheuen viele Unternehmen nach wie vor den Umgang mit Textdaten. Je nach Dokumentenart sind die Textinhalte und sich daraus ergebende Implikationen schnell ersichtlich, oder bedürfen einer zeit- und ressourcenintensiven manuellen Durchsicht. Dabei ist insbesondere für letzteres Szenario die Möglichkeit der (teil-)automatisierten Textanalyse von Vorteil. Insbesondere im industriellen Kontext gibt es eine Vielzahl an Anwendungsfelder für Text Mining: die Überprüfung und Bewertung von Stammdaten in Textform, die Klassifikation von Textdokumenten (z.B. Angebote oder Patentschriften) oder die Analyse sämtlicher, textbasierter Kundenkommunikation (gerichtet, d.h. in Form von E-Mails oder Chat-Protokollen und ungerichtet, d.h. in Form von User-Generated-Content in Social Media).

Was machen wir im März?
Nächsten Monat wollen wir die unternehmerischen Anwendungsfelder von Text Mining noch genauer betrachten. Basierend auf unserer langjährigen Erfahrung im Bereich der Textanalyse und der Zusammenarbeit mit Kunden unterschiedlicher Branchen berichten wir von Fragestellungen und Erfolgen, die wir mithilfe von Text Mining beantworten und erzielen konnten. „Text Mining konkret: Von der Produktentwicklung bis zur Vertriebssteuerung, alles gehorcht aufs Wort“. Wir hoffen, wir können Sie inspirieren!
Themenübersicht:
- Anfang Oktober: "Los geht’s: Was erwartet Sie in den nächsten Monaten?"
- Anfang November: "Data Science versus Data Analytics"
- Anfang Dezember: "Big Data oder: Viel hilft viel?!"
- Anfang Januar: "Künstliche Intelligenz versus Machine Learning"
- Anfang Februar: "Text Mining: Weil lesen einfach (zu lange) dauert"
- Anfang März: "Text Mining konkret: Von der Produktentwicklung bis zur Vertriebssteuerung, alles gehorcht aufs Wort"
- Anfang April: "Predictive Analytics: Heute wissen, was morgen passiert"
- Anfang Mai: "Predictive Analytics konkret: Vom Personaleinsatz bis zum Maschinenstillstand, alles ist planbar"



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}