
Die Anwendung von Predictive Analytics findet nicht nur im produzierenden Gewerbe und in den Bereichen Supply Chain & Manufacturing Anklang. Auch im Dienstleistungssektor und innerhalb der Bereiche Marketing und Sales profitiert man von der Prognose zukünftiger Ereignisse. In der Luftfahrtindustrie werden beispielsweise Flugpreise, Sitzkontingente, Abflugzeiten und das Abflugdatum mithilfe von Predictive Analytics bestimmt. In dem nachfolgenden Beitrag möchten wir Ihnen die grundlegenden Begriffe und Vorgehen im Bereich Predictive Analytics näherbringen.
Descriptive, Diagnostic, Predictive oder Prescriptive?
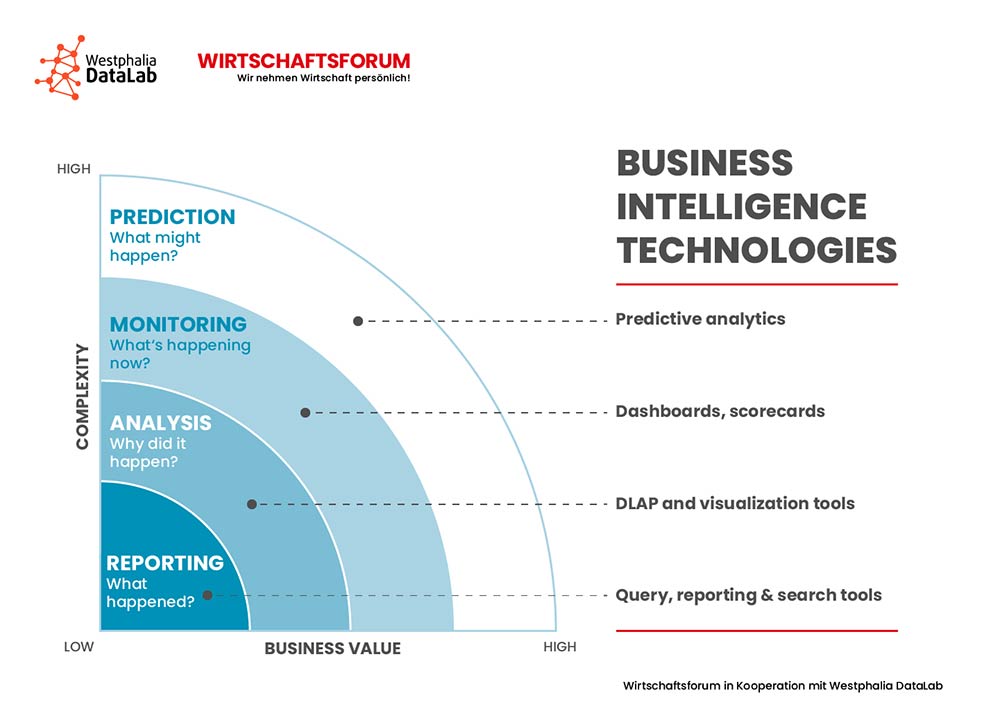
Predictive Analytics zählt zu den wichtigsten Anwendungsgebieten von Big Data und setzt da an, wo klassisches Business-Intelligence-Reporting aufhört. Business Intelligence (BI) wird oft als Oberbegriff für jegliche Form der zielgerichteten Datenanalyse im Unternehmen verwendet. Unter BI werden sämtliche Verfahren zur systematischen Sammlung, Auswertung und Darstellung von Daten im unternehmerischen Kontext zusammengefasst, die vordergründig zur Effizienzsteigerung und Wertschöpfung dienen. Dank BI können operative und strategische Entscheidungen datenbasiert unterstützt und Unternehmensziele schneller und wirksamer erreicht werden. Diese Entscheidungen basieren dabei auf der Interpretation von Vergangenheitsdaten. In diesem Zusammenhang lassen sich mit den Standard-BI-Tools folgende Fragen beantworten: Was ist passiert? Warum ist es passiert? Oder im Fall von Monitoring-Projekten: Was passiert jetzt gerade? Predictive Analytics geht einen Schritt weiter und trifft, basierend auf den Vergangenheitsdaten, Annahmen über die Zukunft: Was wird passieren?

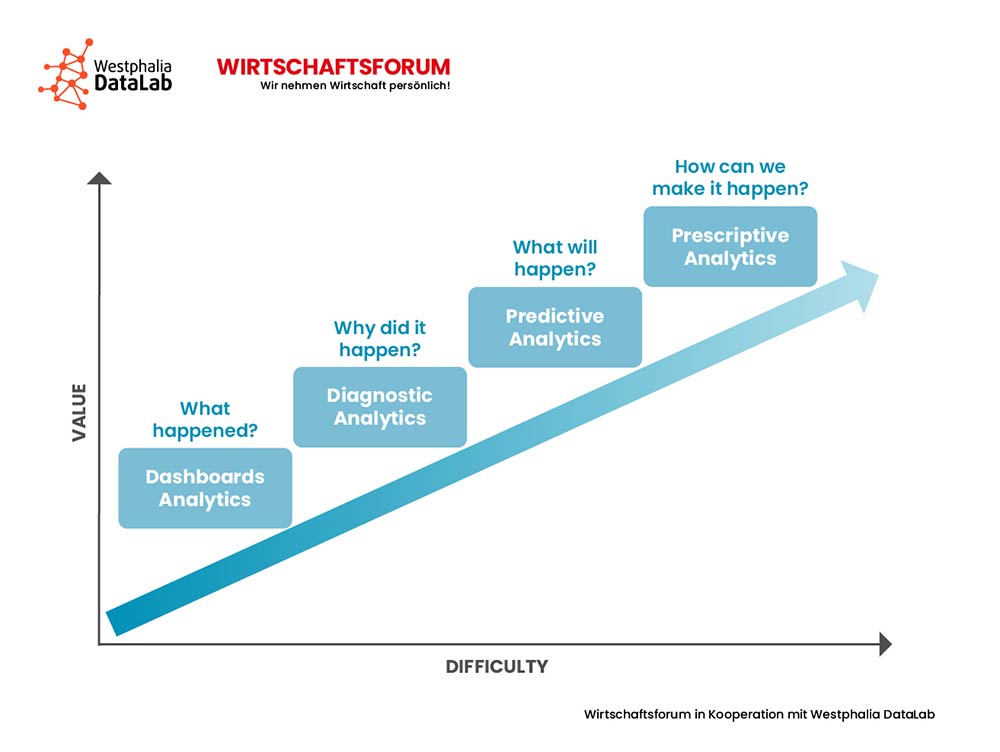
Neben Predictive Analytics existieren folgende weitere Konzepte: Im Bereich Descriptive Analytics werden bestehende Daten i.S. einer Bestandsaufnahme analysiert und ein Status Quo abgeleitet: Wie ist die Lage? Im Vergleich dazu steht der Begriff Diagnostic Analytics für den Einsatz sämtlicher Verfahren mit dem Ziel der Ursachenforschung: Warum ist der Status Quo so, wie er ist? Wie bereits eingangs erwähnt, steht Predictive Analytics für vorausschauende oder vorhersagende Analysen: Was wird passieren? Einen Schritt weiter in die Zukunft geht man innerhalb des Bereiches Prescriptive Analytics. Analog zu der Symptom-Ursache-Beziehung zwischen Descriptive Analytics und Diagnostic Analytics ist es die Aufgabe von Prescriptive Analytics, zukünftige Ereignisse zu erklären und zu simulieren. Die vier verschiedenen Konzepte unterscheiden sich in Aufwand und Aussagekraft bzw. Business Value.

Mit ein paar Schritten in die Zukunft
Analog zu dem Vorgehen innerhalb der bereits vorgestellten Analyseverfahren und Use Cases im Bereich Text Mining gibt es auch bei der Anwendung von Predictive Analytics ein schrittweises Vorgehen.
Im ersten Schritt werden Rohdaten bzw. Vergangenheitsdaten gesammelt. Da i.d.R. kein Unternehmen über Daten aus der Zukunft verfügt, beziehen sich die Begriffe Rohdaten und Vergangenheitsdaten auf ein und dasselbe: Daten. Im einfachsten Fall liegen die Daten bereits in strukturierter Form in Dateien vor oder können aus einer Datenbank exportiert werden. Die vorliegenden Daten dienen als Grundlage, auf Basis derer Muster abgeleitet und diese Muster auf neue, noch nicht bekannte Daten angewendet werden. Das Ganze kann man sich wie eine Art Schablone vorstellen: Wenn in der Vergangenheit um die Osterzeit Schokohasen verkauft wurden, dann ist das ein Muster, auf das der neue, noch unbekannte Datensatz getestet wird: Lässt sich der Verkauf von Schokohasen in der Osterzeit auch in den neuen Daten beobachten? Eine gute Schablone setzt sich dabei aus allen möglichen Mustern zusammen, die im bekannten Datensatz vorhanden sind und im Rahmen einer Prognose eine Rolle spielen könnten. Das bedeutet für die Auswahl der Daten, dass diese so umfangreich wie möglich sein müssen. Viele Daten erhöhen die Chance, dass alle Muster, sofern es denn welche gibt, abgedeckt werden.
In der Phase Datenaufbereitung und Datenexploration werden die Daten von Inkonsistenzen bereinigt und explorativ untersucht. Im Rahmen der Untersuchung werden die Daten mithilfe grundlegender deskriptiver Statistik analysiert und visualisiert, um individuelle Annahmen über Zusammenhänge und Auffälligkeiten innerhalb der Daten zu validieren. Hier kommt auch die gute alte Bekannte Korrelation mit ins Spiel. Mithilfe einer Korrelationsanalyse lassen sich beispielsweise Annahmen über Zusammenhänge auf statistische Signifikanz prüfen und neue, bisher nicht vermutete Zusammenhänge aufdecken.
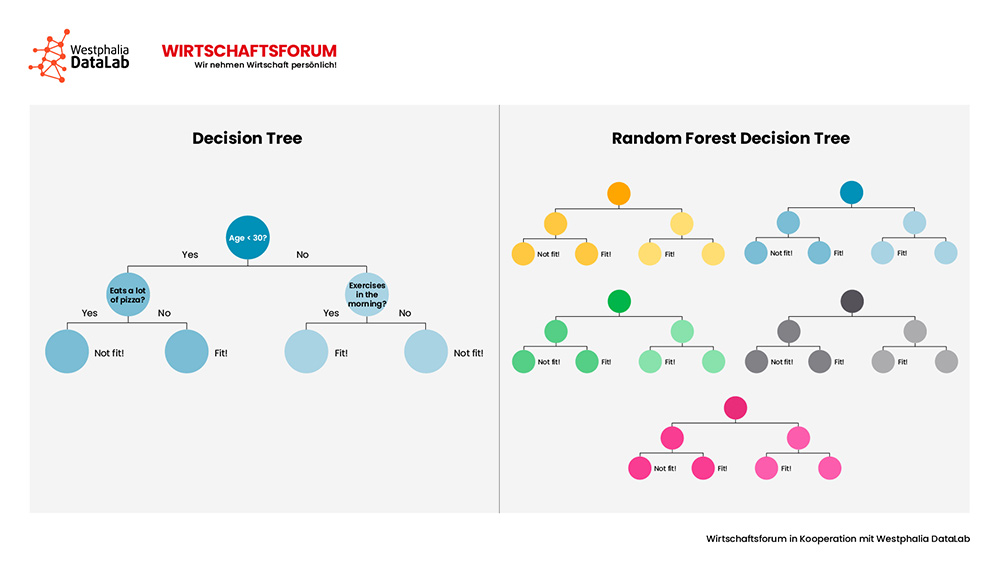
Im Vorfeld der Modellbildung werden die Daten (Total Set) zunächst in Trainings- und Testdaten unterteilt (Trainings Set, Test Set). Basierend auf dem Trainingsdatensatz lernt das Modell, welche Muster in den (Trainings-)Daten vorhanden sind. Diese Erkenntnisse (Schablone) werden später auf dem Testdatensatz vertestet und, sofern erfolgreich, später auf noch unbekannte Daten angewendet. Üblicherweise wählt man ein Verhältnis von 80:20 oder 70:30 für das Training/Testen. Für die eigentliche Modellbildung (das Lernen) stehen verschiedene Algorithmen zur Verfügung. Die Lineare Regression dürfte so manchem noch aus Schulzeiten bekannt sein. Es handelt sich dabei um ein statistisches Verfahren, mit dem versucht wird, eine beobachtete abhängige Variable durch eine oder mehrere unabhängige Variablen zu erklären. Ein Nachteil dieses Algorithmus ist, dass komplexe Zusammenhänge nicht abgebildet werden können. Für die Abbildung komplexer Zusammenhänge eignen sich Entscheidungsbäume. Je nach Komplexität gibt es einfache Entscheidungsbäume (Decision Trees), randomisierte Entscheidungsbäume (Random Forest Decision Trees) oder „geboostete“ Entscheidungsbäume (Gradient Boosted Decision Trees). Nicht zuletzt können auch Neuronale Netze für Predictive-Analytics-Fragestellungen hinzugezogen werden. Nicht selten bedarf es einer Kombination aus mehreren Algorithmen.

Aktienkurse, Lottozahlen, EM-Gewinner…
Laut einer Studie des Business Application Research Centers (BARC) kommen bei nur 5% von 210 befragten Unternehmen, ungeachtet des großen wirtschaftlichen Potentials und der Bandbreite der Anwendungsmöglichkeiten, Predictive Analytics regelmäßig zum Einsatz. Immerhin planen fast 45% der befragten Unternehmen kurz- bzw. langfristig die Nutzung derartiger fortgeschrittener Analysen. Fast 100% der befragten Unternehmen schätzen die Anwendung von Predictive Analytics als sehr wichtig ein und haben vor, in naher Zukunft erste Schritte in diese Richtung zu gehen.
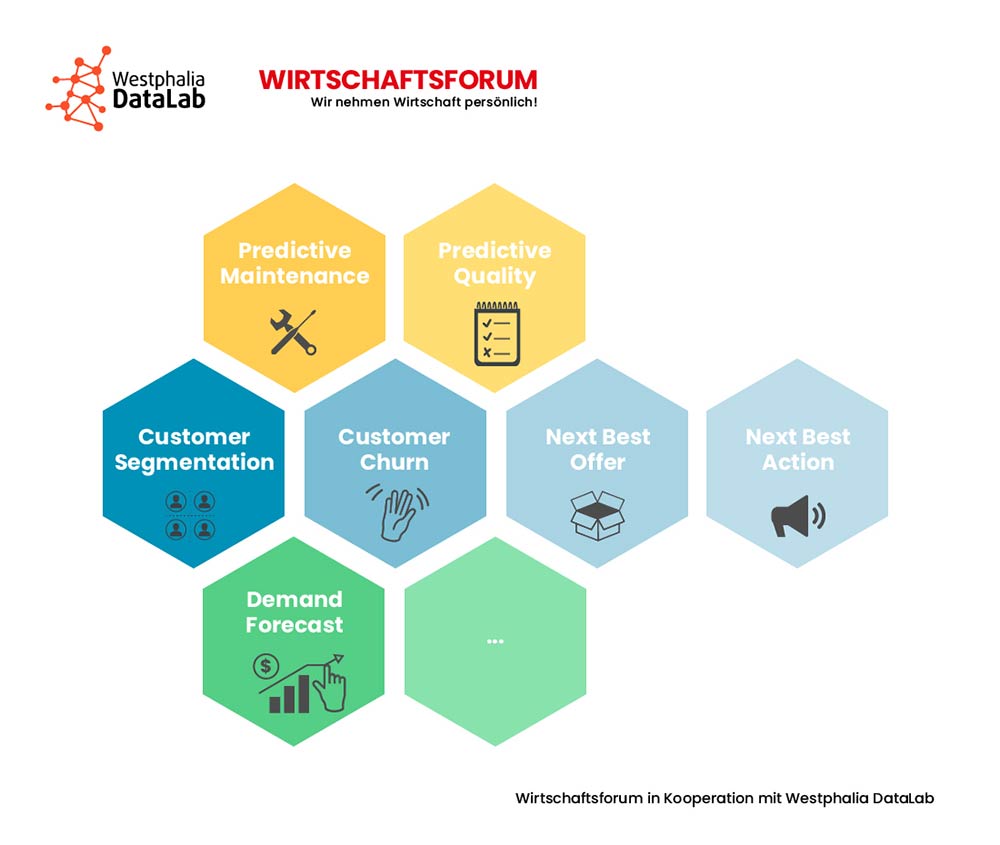
Die Unternehmen, die bereits Predictive Analytics im beruflichen Alltag anwenden, tun dies in verschiedensten Kontexten. Übertragen in die Praxis sind potenzielle Einsatzgebiete z.B. Predictive Maintenance, d.h. die Vorhersage kritischer Maschinenfehler und sich daraus ergebende Stillstände. Basierend auf dem Wissen können bereits vor dem eigentlichen Fehleraufkommen oder Stillstand korrektive Maßnahmen ergriffen werden. Doch nicht nur der Produzent kann von dieser Analysemöglichkeit profitieren. Daneben bietet der Use Case Predictive Maintenance auch das Potential als neues, digitales Geschäftsmodel von Instandhaltungsdienstleistern oder als Zusatzleistung eines Maschinenbauers angeboten und vermarktet zu werden. Neben dem produktionsnahen Anwendungsbereich lassen sich auch im Bereich Sales Potentiale durch Predictive Analytics heben. So ist es dank prädiktiver Analyse möglich, zukünftige Absätze vorherzusagen. Im Rahmen von sogenannten Forecasting-Projekten werden, basierend auf historischen Verkaufszahlen und unter Einbezug externer Faktoren (je nach Use Case z.B. Wetter, Ferienzeiten, Feiertage) zukünftige Verkaufszahlen prognostiziert. Über die bloße Verkaufszahl hinausgehend kann dank Predictive Analytics sogar für jeden Kunden das nächst beste Produkt (Next Best Offer) oder die nächst beste Ansprache i.S. einer Kampagne (Next Best Action) prognostiziert werden, heißt: Unternehmen wissen nicht nur, wieviel Kunden zukünftig kaufen, sondern auch was und wodurch sie sich zum Kauf anregen lassen. Auch in den Branchen Life Science & Healthcare lassen sich für Predictive Analytics spannende Anwendungsszenarien finden. Dank der entsprechenden Verfahren können Krankheitsverläufe vorhergesagt und so die eigentliche Diagnostik und Therapie unterstützt werden. So gesehen ist Predictive Analytics eines der „fruchtbarsten“ Analyseverfahren.

Wie bei jeder anderen Analysemethode birgt auch die Anwendung von Predictive Analytics Risiken in sich und stellt Unternehmen vor Herausforderungen. Wie bereits angesprochen, ist die Vorhersage zukünftiger Ereignisse maßgeblich von Mustern in historischen Datensätzen abhängig. Das bedeutet, dass es zum einen überhaupt Muster innerhalb der Daten geben muss und diese Muster auch innerhalb des Trainingssets abgebildet sein müssen. Für die Kompilation der Datenbasis bedeutet dies einiges an Aufwand, bevor es überhaupt mit der Analyse losgehen kann. Beispielsweise ist die Prognose der Absatzmenge von Schokohasen in der Osterzeit vordergründig für die Berechnung der Lager- und Maschinenkapazität sowie der Preisdynamik wichtig. Allerdings spielen dabei nicht nur die reinen Lager- und Verkaufszahlen eine Rolle, sondern vor allem zusätzliche Informationen und Daten aus dem Marketing: Wann wurde die letzte Kampagne geschaltet, wann findet die nächste statt? Gab es Rabatt-Aktionen, wenn ja, wann gibt es die nächsten? Wie ist der Verkaufsanteil bezogen auf Online -Shops und Retail? Selbst diese einfache Fragestellung bringt also einen nicht unerheblichen Aufwand an Vorüberlegungen mit sich. Demgegenüber gibt es auch Use Cases, die zwar sehr verlockend klingen, aber deren Umsetzung schlichtweg nicht möglich ist. So lassen sich Aktienkurse, Lottozahlen oder der nächste EM-Gewinner nicht auf Basis von Vergangenheitsdaten vorhersagen. Der Verlauf eines Aktienkurses ist beispielsweise von vielen Parametern abhängig, deren zukünftige Ausprägungen nicht antizipierbar sind und deren Bündelung in einer Datenbasis entsprechend unmöglich ist.
Fazit
Daten gehören zum wichtigsten Kapital eines Unternehmens. Sie bilden die Basis für zielführende und robuste unternehmerische Entscheidungen und können zu einem Wettbewerbsinstrument werden. Fortschrittliche Analysen wie Predictive Analytics versuchen die Zukunft vorauszusagen, und zwar ganz ohne Glaskugel. Die Basis dafür ist die sorgfältige Datenauswahl und Analyse bisherigen Verhaltens. Dabei darf nicht vergessen werden, dass der Blick in die Zukunft nur dann funktioniert, wenn auch tatsächlich Muster in der Vergangenheit aufgetreten sind. Doch egal wie präzise ein Modell die Zukunft vorhersagen kann: Der letzte Schritt ist immer noch der gesunde Menschenverstand, denn jede Vorhersage ist und bleibt eine statistische Analyse.
Was machen wir im Mai?
Im nächsten Beitrag erfahren Sie mehr zum Thema „Predictive Analytics konkret: Vom Personaleinsatz bis zum Maschinenstillstand, alles ist planbar“. In unserem Mai Beitrag möchten wir Ihnen anhand konkreter Projektbeispiele zeigen, wie auch Sie als Unternehmen aus der Vergangenheit für die Zukunft lernen können.



{kind=link}
{kind=link}
{kind=link}
{kind=link}