
Wer oder was sind Daten und wieviele gibt es?
Ein Datum repräsentiert zunächst einmal eine qualitative Angabe oder einen quantitativen Wert. Ende der 80er Jahre waren noch weniger als ein Prozent aller Daten digital verfügbar, heute hat sich das Verhältnis umgekehrt und nur noch 1 Prozent aller Daten sind analog vorhanden. Der Marktstudie „Data Age 2025“ von Seagate folgend beträgt die weltweite Datenmenge aktuell etwa 33 Zetabyte (ZB). Ende des Jahres 2019 spricht dann entsprechend keiner mehr von einzelnen Bits, sondern alle reden von „Big Data“. Bis zum Jahr 2025 soll die Menge an digital verfügbaren Daten um mehr als das fünffache steigen.

Bereits 2017 hat jeder Mensch im Durchschnitt täglich über 600 MB Daten erzeugt, inzwischen sind es mehr als ein Gigabyte pro Tag. Bezogen auf über 7,5 Milliarden Menschen i.S.v. Datenproduzenten ergibt sich eine unvorstellbare Menge an Daten, die täglich wächst. Diese Menge wird nicht nur über soziale Netzwerke, Messenger-Dienste oder durch die Verwendung von Suchmaschinen erzeugt, sondern beispielsweise auch durch die Nutzung der Krankenkassenkarte, durch das Versenden von E-Mails, die Nutzung von Kredit- oder Kundenkarten oder beim Online-Shopping. Neben den Daten, die der Mensch ganz beiläufig in seinem privaten Alltag produziert, steuern auch Unternehmen zahlreiche Daten bei, u.a. Standortinformationen, Logistik- oder Maschinendaten.
Wie wird Datenmenge gemessen und ab wann ist „Data“ denn „Big“?
Der aus dem englischen Sprachraum stammende Begriff „Big Data“ bezieht sich auf mehr als nur eine Eigenschaft. Auf der einen Seite referiert der Begriff auf die rasant wachsende Datenmenge, auf der anderen Seite wird durch den Begriff in einem Zuge auch auf neue und leistungsstarke Technologien zur Verarbeitung und Auswertung eben jener Datenmenge hingewiesen. „Big Data“ bezeichnet Daten, die üblicherweise im Volumen überdurchschnittlich groß (Volume), deren Geschwindigkeit der Generierung und Übertragung außerordentlich schnell (Velocity), und deren Vielfalt bezogen auf die vorliegenden Datentypen heterogen (Variety) ist. Unternehmen sprechen schon ab der Einheit Terabyte (TB) von „Big Data“, einen harten Schwellwert für die Nutzung des Begriffes gibt es nicht.

"Big Data“ ensteht nicht aus dem Nichts.
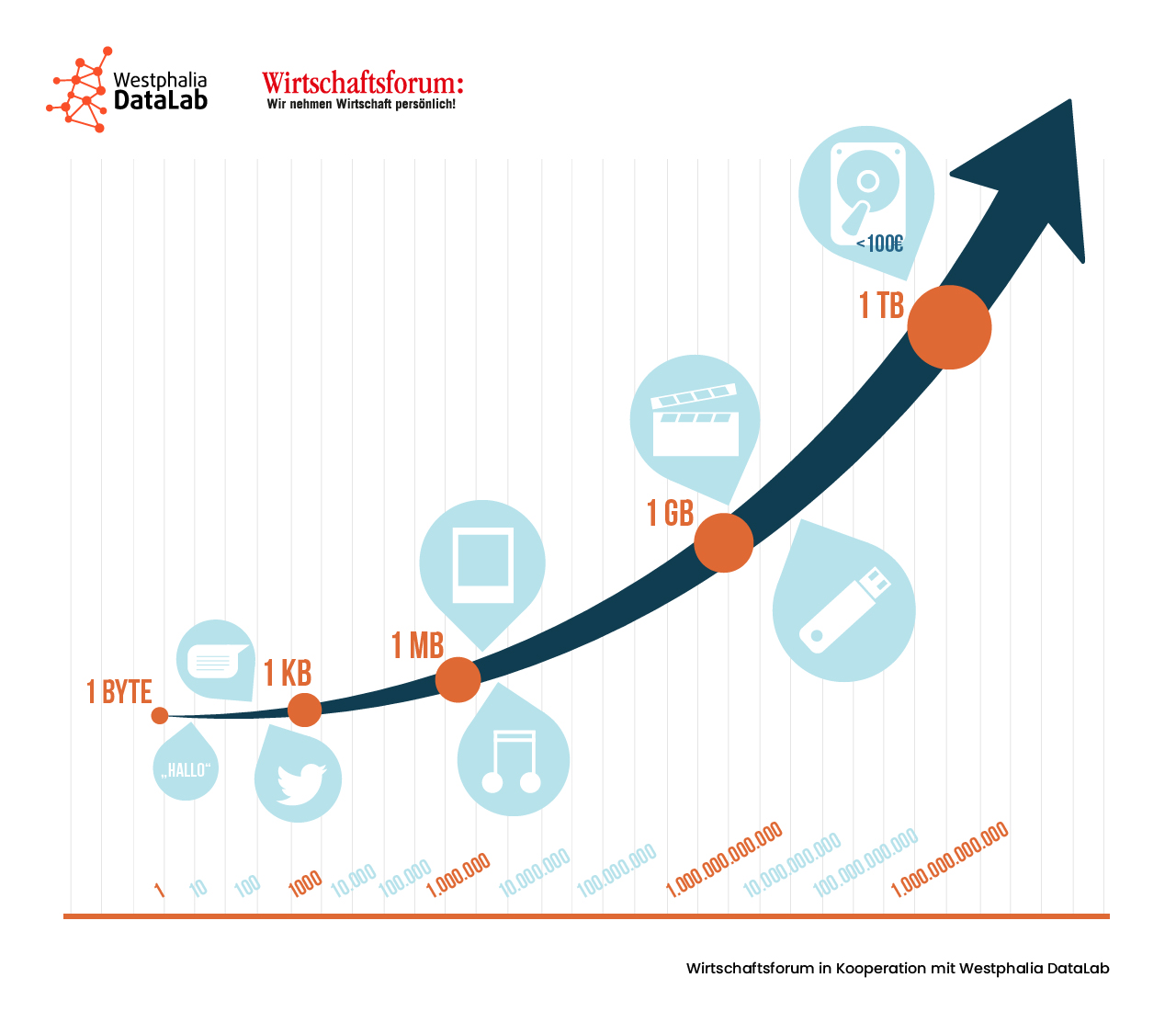
Am Anfang steht ein Bit (Binary Digit). Ein Bit ist die kleinste elektronische Speichereinheit bei Computern und bezeichnet einen von zwei möglichen Zuständen: AN oder AUS respektive 1 oder 0. Da bei der Nutzung von Computern i.d.R. ganze Zahlen, Buchstaben oder Wörter abgespeichert werden, werden mehrere Bits zu einer Speichereinheit zusammengefasst. Zum Beispiel ergeben 8 Bits (2^3) ein Byte. In einem Byte sind also acht Plätze mit jeweils zwei möglichen Zuständen vorhanden. In einem Byte ist somit Platz für 2^8 = 256 verschiedene Buchstaben oder Zahlen. Unter der Verwendung von mehreren Bytes können dann komplexere Sachverhalte wie etwa Wörter oder Sätze ausgedrückt werden.
Im nächstgrößeren Maßeinheits-Schritt ergeben 1024 Byte ein Kilobyte (KB). Ab jetzt geht es immer mit dem 1024f-achen der vorherigen Einheit weiter zur nächsten Größe:
- Megabyte (MB),
- Gigabyte (GB),
- Terabyte (TB),
- Petabyte (PB),
- Exabyte (EB),
- Zetabyte (ZB),
- Yottabyte (YB)
Ein Yottabyte enthält etwa 10^24 Byte, was ungefähr 1.208.925.819.614.629.200.000.000 Byte entspricht. Die eben genannten 33 ZB an aktuell weltweit gespeichertem Datenvolumen entsprechen demnach ungefähr 38.959.523.483.674.570.000.000 Bytes.
Aber wie genau kann man sich das jetzt vorstellen?
- Ein durchschnittlich langes Wort ist 10 Byte groß,
- eine SMS besteht aus 160 Byte,
- ein Tweet besteht aus 280 Byte,
- ein Foto durchschnittlicher Qualität ist etwa 4 MB groß,
- ein normal langes Lied benötigt etwa 6 MB Speicherplatz,
- für einen HD-Qualitätsfilm benötigen Sie einen 1,2 GB bis 10 GB großen Datenträger,
- standardmäßige USB-Sticks sind inzwischen 64 GB bzw. 128 GB groß,
- und inzwischen gibt es externe Festplatten in Terabytegröße für unter 100Euro.

Wofür brauchen wir „Big Data“?
Oberstes Ziel bei der Entwicklung von Online-Übersetzungsprogrammen ist die Entwicklung einer Art „Babelfischs“, wie ihn Douglas Adams in seinem Ende der 70er erschienen Buch „Per Anhalter durch die Galaxis“ beschrieb. Ins Ohr eingesetzt leistet dieser in der Science-Fiction-Geschichte gute Dienste und übersetzt für seinen Nutzer simultan alle erdenklichen Sprachen. Eine Vorstellung, die für uns heute tatsächlich nur noch wenig mit „Fiction“, aber umso mehr mit „Science“ zu tun hat. Aber warum ist „Big Data“ wichtig, wenn man gerne einen einzelnen japanischen Fachtext ins Spanische übersetzen lassen möchte?
Wissenschaftler von IBM beschäftigten sich in den 50er Jahren damit, maschinelle Übersetzungen zu entwickeln. 1954 gelang es dann, 250 Wörter und sechs Grammatikregeln vom Russischen ins Englische zu übersetzen. Ende der 80er Jahre erzielten die Ingenieure von IBM mit einem neuen Ansatz einen weiteren Erfolg. Der Computer sollte jetzt selbst, d.h. anhand von fertigen (und korrekten) Übersetzungen lernen, wie ein Satz übersetzt werden kann. Die Computer wurden mit vorliegenden Textdokumenten in zwei Sprachen gefüttert, um zu lernen, mit welcher Wahrscheinlichkeit Begriffe auf eine bestimmte Art übersetzt werden und für einen entsprechenden Satzbau genutzt werden können. Der Start der statistischen maschinellen Übersetzung.
Doch je nach Sprache unterscheiden sich Semantik und Grammatik erheblich voneinander. Die Lösung sind künstliche Neuronale Netze (KNN), mit denen nicht mehr einzelne Wörter, sondern ganze Phrasen, Sätze und Abschnitte kontextabhängig übersetzt werden können. Dabei werden Wörter als hochdimensionale Vektoren verstanden, wobei kontextähnliche Wörter im Vektorraum näher beieinander liegen als solche, die sich unterscheiden. Google Translate ging mit einem solchen Ansatz 2006 ins Rennen. Basierend auf Milliarden von Wörtern aus unterschiedlichen Sprachen und Kontexten geht es nun nicht mehr um das semantische Verstehen der Textinhalte, sondern um die Berechnung blanker Wahrscheinlichkeiten.
Auch die Entwicklung von Online-Kartendiensten ist „Big Data“ zu verdanken. Die Möglichkeit Echtzeit-Verkehrsinformationen wie Stau- und Unfallmeldungen abrufen zu können basiert auf Crowdsourcing: Andere Nutzer, die am Verkehrsgeschehen teilnehmen, produzieren Standortinformationen, welche live verarbeitet werden. So wird stockender Verkehr und Stau direkt registriert und an alle Nutzer weitergegeben. Dies wäre ohne eben jene Datenmengen nicht möglich, denn wie soll sonst unterschieden werden, ob ein Autofahrer ggf. einfach nur eine Pause macht oder ob es sich tatsächlich um Stau handelt?
Daneben wird „Big Data“ auch zur Verbrechensbekämpfung eingesetzt. Im 2002 erschienenen Film „Minority Report“ wurde das Thema Predictive Policing bereits zuschauertauglich aufbereitet. Im Film werden Menschen verhaftet, die ein Verbrechen geplant, aber noch nicht umgesetzt haben. Von Hollywood nach Hessen: In Hessen wird die Software der Firma Palantir eingesetzt, um geplante Verbrechen tatsächlich rechtzeitig aufdecken und verhindern zu können. Mit Hilfe großer Datenmengen, statistischer Auswertungen und Profiling-Algorithmen werden verdächtige Personen oder Gegenden identifiziert. Auch in den USA, Großbritannien und Teilen Italiens wird diese neue Form der Polizeiarbeit eingesetzt, um Polizeistreifen gezielt einsetzen zu können.
Für Unternehmen ergeben sich ebenso Chancen durch „Big Data“ im beruflichen Kontext. Basierend auf vielen unterschiedlichen Daten können beispielsweise Prognosen über zukünftige Absatzentwicklungen oder künftiges Kaufverhalten berechnet werden. Detailliertes Wissen über Kunden, und zwar nicht nur das Kaufverhalten betreffend, kann bei der Entwicklung und dem Vertrieb kundenindividueller Produkte genutzt werden. Die gleichzeitige Auswertung von Produkt- und Produktionsdaten gepaart mit regionalen Informationen über Standorte und deren Demographie ermöglichen datenbasierte Entscheidungen über Standorteröffnungen und Routen. Auch im Bereich des nicht-produzierenden Gewerbe, beispielsweise in Kliniken und Krankenhäusern, wird „Big Data“ genutzt. So besteht die Möglichkeit durch den Einsatz von „Big Data“ Krankheiten, deren Verlauf und Verbreitung vorherzusagen.
Erfolgreich mit „Small Data“?
So wertvoll große Datenmengen auch sind, so schwierig ist deren Erhebung sowie die zielgerichtete und nutzenstiftende Analyse dieser. Fast jedes zweite Unternehmen in Deutschland, Österreich und der Schweiz hat hier Probleme. Laut der „Business Intelligence & Analytics-Studie biMa“ 2017/2018, durchgeführt von Sopra Steria Consulting und BARC, wurden mehr als 300 Unternehmen unterschiedlicher Branchen und Größen zum Thema „Big Data“ befragt. Mehr als ein Viertel aller befragten Unternehmen gab dabei Probleme im Rahmen der Erhebung und Integration von Daten aus unterschiedlichen Quellen an. Weiterhin fehlt in Unternehmen das fachliche Verständnis für die Analyse eben jener großen Datenmengen, und die Beauftragung externen Beratungsfirmen oder Experten ist nicht selten mit enormen Zeit- und Kostenaufwänden verbunden. Zusätzlich wird die Analyse der Daten durch bestehende Datenschutzrichtlinien innerhalb und außerhalb des Unternehmens erschwert.
Immer mehr Unternehmen setzen daher nicht mehr nur auf „Big Data“, sondern bevorzugen für die Analyse „Small Data“. Denn es kommt nicht immer nur auf die Menge an, sondern vor allem auf die Relevanz der Daten. Man kann also durchaus auch mit „Small Data“ Erfolge erzielen, und manchmal sogar wertvollere Insights gewinnen, als über die bloße Masse. Ein gutes Beispiel hierfür ist die Analyse von Kundenfeedback. Unternehmen analysieren Kundenfeedback i.S.v. Textdaten um beispielsweise herauszufinden, welche Probleme der Kunde im Feld beschreibt, oder was dem Kunden an einem Produkt gefällt, oder eben nicht. Dabei sind die Themen, über die die Merheit der Kunden spricht, natürlich wichtig, aber i.d.R. nicht wirklich eine Überraschung für Unternehmen. Richtig intertessant wird es eigentlich, wenn es gelingt die Themen zu identifizieren, über die nur zwei, drei Kunden sprechen. Gute Ideen entstehen nie in 1.000 Köpfen gleichzeitig, sondern eher in einem. Um einen Wettbewerbs-vorsprung zu erzielen und innovative Produkte zu entwickeln ist es also umso wichtiger, sich auch mal auf „Small Data“ einzulassen.

Was macht das WDL mit „Big Data“?
Im Westphalia DataLab (WDL) haben wir es täglich mit großen, mittelgroßen und kleinen Datenmengen zu tun, die es im Auftrag des Kunden zu analysieren gilt. Dabei handelt es sich sowohl um interne Unternehmensdaten sowie externe Daten, die bei Bedarf erhoben, integriert und in die Analyse mit einbezogen werden. Mit Hilfe von Machine Learning (ML) sowie Verfahren der Künstlichen Intelligenz (KI) werden in den Daten neue Informationen entdeckt, Lösungen formuliert und Prozesse verbessert. Gemeinsam mit dem Kunden schaffen wir durch die Datenanalyse eine bessere Entscheidungsgrundlagen für die Optimierung verschiedensten Geschäftsprozesse.

Was erwartet Sie im nächsten Monat?
Im WDL setzen wir im Rahmen der Datenanalyse u.a. Verfahren des Machine Learnings sowie der Künstlichen Intelligenz ein. Aber was ist eigentlich Künstliche Intelligenz, und was ist der Unterschied zwischen KI und Machine Learrning? Und was wurde aus Korrelation, Regression und Co.?
Bis dahin wünschen wir Ihnen frohe Feiertage und einen guten Rutsch ins Jahr 2020.
Themenübersicht:
- Anfang Oktober: "Los geht’s: Was erwartet Sie in den nächsten Monaten?"
- Anfang November: "Data Science versus Data Analytics"
- Anfang Dezember: "Big Data oder: Viel hilft viel?!"
- Anfang Januar: "Künstliche Intelligenz versus Machine Learning"
- Anfang Februar: "Text Mining: Weil lesen einfach (zu lange) dauert"
- Anfang März: "Text Mining konkret: Von der Produktentwicklung bis zur Vertriebssteuerung, alles gehorcht aufs Wort"
- Anfang April: "Predictive Analytics: Heute wissen, was morgen passiert"
- Anfang Mai: "Predictive Analytics konkret: Vom Personaleinsatz bis zum Maschinenstillstand, alles ist planbar"



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}