Künstliche Intelligenz versus Machine Learning
Gefährliche Bedrohung oder perfekte Chance?

In Filmen übertrifft die maschinelle Intelligenz die menschliche und entwickelt sich stetig auf eigene Faust zu einer Superintelligenz weiter. Derartige Bedrohungsszenarien erheben die Frage nach digitaler Verantwortung und einer seriösen Technikfolgenabschätzung. Auf der anderen Seite ist unser Leben ohne die Hilfe von KI so nicht mehr realisierbar. KI heißt nicht nur, dass Computer den menschlichen Weltmeister im Schach oder Go besiegen oder inzwischen selbstfahrende Autos auf den Straßen anzutreffen sind, sondern auch die Anwendung von intelligenten E-Mail-Systemen, Übersetzungsprogrammen, intelligente Wortergänzung bei Suchmaschinen oder Navigationssystemen. Und das ist nur ein kleiner Auszug der Annehmlichkeiten, die wir tagtäglich, ohne darüber nachzudenken, nutzen und schätzen.
Die technologische Singularität, d.h. der Punkt, an dem die künstliche die menschliche Intelligenz übertrifft und sich von da an selbst verbessert, ist noch weit entfernt. Die meisten KI-Systeme sind spezialisiert auf eng definierte Aufgabenbereiche: Googles AlphaGo oder der Supercomputer Deep Blue sind unantastbare Experten im Go bzw. Schach, allerdings auf dieses Gebiet beschränkt. Während Menschen über Allgemeinwissen, Vorerfahrung, Intuition, Adaption und Rituale mit Bezug auf verschiedene Wissensdomänen verfügen, ist dieses Wissen für Computer aktuell nicht zugänglich. Ein KI-System ist real und die schnelle und fehlerfreie Rechenleistung durchaus beeindruckend, allerdings versteht die KI nicht, was sie tut und warum. Das ist der bedeutende Unterschied zwischen der künstlichen und der menschlichen Intelligenz.

Wo nutzen wir KI?
KI hat einen großen Einfluss auf unser tägliches Leben und wird inzwischen in vielen Bereichen eingesetzt. Egal, was wir am Computer, Handy oder Tablet machen, die KI trifft im Hintergrund bereits auf Basis unseres Verhaltens und unserer Vorlieben Entscheidungen, die unsere Benutzererfahrung verbessern sollen:
- Sind wir früher zum Teil mit großen, auf dem Lenkrad ausgebreiteten, Straßenkarten von A nach B gefahren, haben bereits die ersten Navigationsgeräte die Kursbestimmung auf den Straßen verändert. Seitdem jetzt zusätzlich noch aktuelle durch andere Nutzer aufgenommene Verkehrsdaten in die Routenermittlung mit einfließen, um Baustellen, Sperrungen und Staus vermeiden und weiträumig umfahren zu können, haben wir eine Vorstellung davon bekommen, was mit KI möglich ist. Navigationssysteme wie etwa Waze, Google Maps oder TomTom Go Mobile suchen zu jedem Zeitpunkt der Fahrt die aktuell schnellste Route, die einen zum Ziel führt.
- KI hat auch die Zukunft des Autos für jedermann sichtbar verändert. Selbstfahrende (oder auch autonome) Fahrzeuge navigieren sich ohne Einfluss eines menschlichen Fahrers durch eine nahezu unendliche Anzahl von Szenarien. Da 90% aller Verkehrsunfälle auf menschliches Versagen zurückzuführen sind, kann auch diese Wahrscheinlichkeit reduziert werden. Der Grad der Autonomie des Autos wird in Stufen von 0 bis 5 eingeteilt, wobei Stufe 5 (“Fahrerloses Fahren vom Start bis Ziel”) weltweit noch nicht erreicht wurde. Level 3-Fahrzeuge können unter gewissen Bedingungen und für einen begrenzten Zeitraum selbstständig und ohne menschlichen Eingriff fahren – und tun es auch. Die USA ist mit Teststrecken für solche Fahrzeuge deutlich weiter als es in Deutschland der Fall ist. Dort sind bereits Level-4-Fahrzeuge auf den Straßen geplant.
- Ein weiterer Bereich der KI ist die automatische Sprachverarbeitung. Der Nutzer kann seinen Wunsch äußern, die Maschinen übersetzen die Anfrage, bearbeiten sie und liefern die gewünschten Ergebnisse. Dies kann eine Navigation zu einer festen Adresse oder zu dem nächsten Supermarkt sein, der Anruf einer Person aus dem Adressbuch kann genauso initiiert werden wie die Auswahl des besten Tierarztes der Region. Geantwortet werden kann als Bild, Text oder auch Sprachausgabe.
- Die E-Mail-Organisation wurde ebenfalls durch den Einsatz von KI verändert: SPAM wird automatisch erkannt, E-Mails werden automatisch sortiert, es gibt Erinnerungen, dass ein Anhang oder Adressat fehlt und intelligente Erinnerungen heben die ungelesenen Mails hervor, die mit großer Wahrscheinlichkeit Aufmerksamkeit benötigen.
- Bei der Verwendung von Suchmaschinen im Internet wie Google, Bing, DuckDuckGo und ähnlichen Anbietern wird KI eingesetzt. Die Suchen werden so immer besser und die Nutzer erhalten immer zuverlässiger das Ergebnis, was für sie die höchste Relevanz hat. So erkennt die KI beispielsweise aufgrund des bisherigen Verhaltens, was mit „Bank“ bzw. mit „Golf“ gemeint ist. Konsumenten können dadurch erheblich Zeit sparen.
- KI revolutioniert auch die Werbung im Internet: Dadurch, dass das Verhalten, die Vorlieben und Interessen der Internetnutzer analysiert werden kann, kann jetzt auch maßgeschneiderte Werbung, sogenannte hyperrelevante Ads erstellt und platziert werden. Interessiert sich ein Nutzer für den Kauf eines neuen Autos, können nicht nur verschiedene Online-Portale angepriesen werden, in denen sowohl das neue Auto gekauft als auch ein möglicherweise vorhandenes altes verkauft werden können, sondern zusätzlich Links zu Kfz-Versicherungen, neuen Sitzpolstern oder günstigen Ad-Blue-Bezugsquellen. Nun ist echtes 1:1-Marketing möglich, da die Werbung den Kunden dabei hilft, bisher unbekannte Produkte zu entdecken, die ihn in seiner aktuellen Lebenssituation wirklich interessieren.
- Auch im Bankwesen wird KI eingesetzt, um maßgeschneiderte Services und individuelle Spar- und Finanzierungspläne anbieten zu können. Dafür können wiederkehrende Zahlungen und das Nutzerverhalten analysiert werden, auch um zusätzlich personalisierte Warnungen und Erinnerungen in die Service einzubinden.
Abkürzungen aus dem KI-Bereich: Wer blickt da noch durch?
Liest man Artikel zum Thema KI, springen dem Leser zahlreiche Abkürzungen und Fachbegriffe ins Auge: KI, AI, ML, NLP, AR, VR, (K)NN, AL, XPS (um nur einige zu nennen). Doch was bedeuten diese Begriffe und welche Aufgaben fallen in welchen Bereich? Wie grenzen sich die Verfahren voneinander ab?
Im Fokus des Beitrages steht neben der künstlichen Intelligenz auch das Machine Learning (ML).
Beides bezeichnen unterschiedliche Schwerpunkte und sind nicht dasselbe, die Begriffe werden allerdings je nach Kontext und Umfeld oft synonym verwendet.
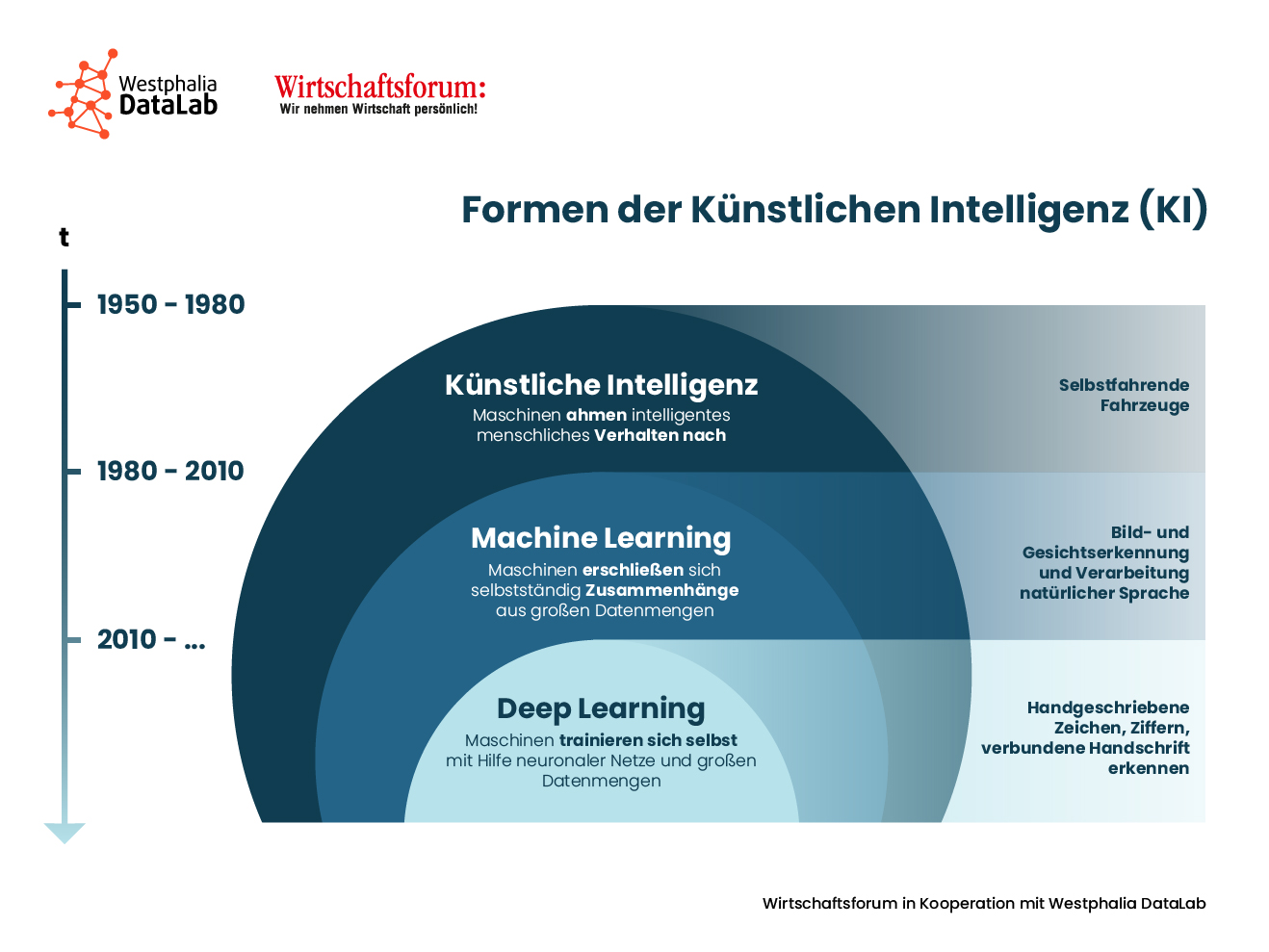
- „In den Medien ist alles KI“: KI ist der geläufigere Begriff in der Praxis, was auch daran liegt, dass die Bandbreite der Felder, die von den Medien als KI bezeichnet wird, sehr breit ist: Nicht nur Deep Learning, ML und Expertensysteme fallen in diesen Bereich. KI bezeichnet allgemein die Fähigkeit von Maschinen intelligentes menschliches Verhalten nachahmen zu können.
- In der Wissenschaft und im Data Science ist ML ein Teilbereich der KI. KI selbst ist jedoch ein sehr großes Forschungsgebiet, das eine Reihe von Techniken umfasst, mit welchen Computer automatisiert lernen und Probleme lösen können. Neben dem ML, welches sich mit dem selbstständigen Erschließen von Zusammenhängen auf Basis von Beispieldaten beschäftigt, umfasst die KI auch noch Robotik, Computerlinguistik, genetische Algorithmen, Computer-Vision und vieles weitere.
- In der Wirtschaft beziehen sich KI und ML in etwa auf das gleiche: Die meisten Geschäftsanwendungen von KI beziehen sich auf ein Teilgebiet des ML: das überwachte Lernen.
Um KI und ML korrekt voneinander abgrenzen zu können, kommt es daher immer darauf an, wen man fragt. Losgelöst vom Anwendungskontext, wird ML als spezialisiertes Teilgebiet der KI verstanden.

Und was ist jetzt Machine Learning und wo wird es eingesetzt?
Machine Learning (ML) ist ein Oberbegriff dafür, dass künstlich Wissen aus Erfahrung generiert wird. Dieser Unterbereich der KI kann als Motor bei vielen Entwicklungen im Bereich der künstlichen Intelligenz verstanden werden. Damit der Motor aber läuft, braucht die ML-Software zunächst die relevanten Daten, Algorithmen und Regeln, um anschließend selbstständig den Datenbestand zu analysieren und Muster bzw. Zusammenhänge erkennen zu können. So können dann
- Relevante Daten gefunden, extrahiert und zusammengefasst werden,
- Vorhersagen getroffen werden und
- Wahrscheinlichkeiten für bestimmte Ereignisse getroffen werden
Ein solches künstliches System lernt nur aus Beispielen und kann dann nach Beendigung der Lernphase auch verallgemeinern. Dazu wird beim ML mit Hilfe der Trainingsdaten ein statistisches Modell aufgebaut, welches Muster in den gegebenen Daten erkennt und lernt. Wichtig für das maschinelle Lernen ist das Vorhandensein riesiger Datenmengen: Wenn eine entsprechende Anzahl an Beispieldaten vorhanden ist, kann ein geeignetes Modell aufgebaut werden. Big Data bildet daher die ideale Basis für diese Art des Lernens. Es ist dabei nicht wichtig, ob es sich dabei um unstrukturierte oder strukturierte Daten handelt. Die angewandten Algorithmen im ML sind für das Erkennen von Mustern und Ermitteln von Lösungen verantwortlich. Es wird zwischen verschiedenen Arten des Lernens unterschieden, wobei für das ML primär überwachtes und unüberwachtes Lernen relevant ist.
Was ist denn überwachtes Lernen?
Beim ML geht es um die Generierung von Wissen aus vorliegenden Daten. Ein System lernt aus Beispieldaten und versucht diese zu verallgemeinern, um später mit dem entwickelten statistischen Modell auch neue Datensätze richtig verarbeiten zu können. Es werden keine Beispiele auswendig gelernt, sondern Muster und Gesetzmäßigkeiten in den vorliegenden Daten identifiziert.
Dazu gibt es zwei Möglichkeiten, wie dies realisiert werden kann:
 Lernen")
Supervised :
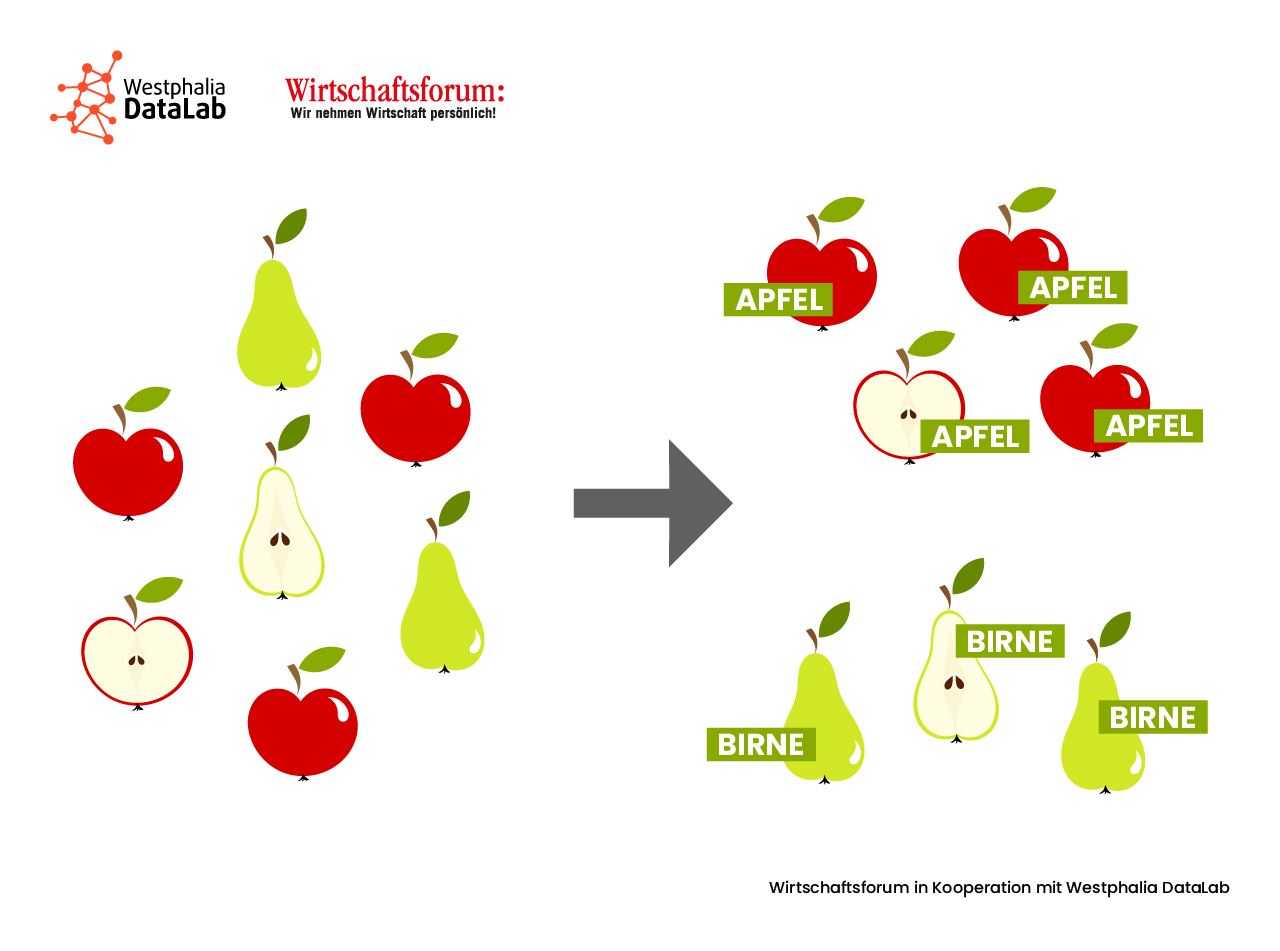
Beim überwachten (supervised) Lernen lernt der Algorithmus durch gegebene Trainingsdaten und Beispielmodelle, welche Eingaben zu welcher Ausgabe führen. Hier wird nun ein künstliches Neuronales Netz (KNN) antrainiert, das anhand der zuvor in mehreren Durchläufen erlernten Gesetzmäßigkeiten jetzt auch neue Daten in die richtige Kategorie einteilen kann. Die Kategorien sind bei diesem Ansatz im Vorfeld festgelegt und bekannt.
Unsupervised :
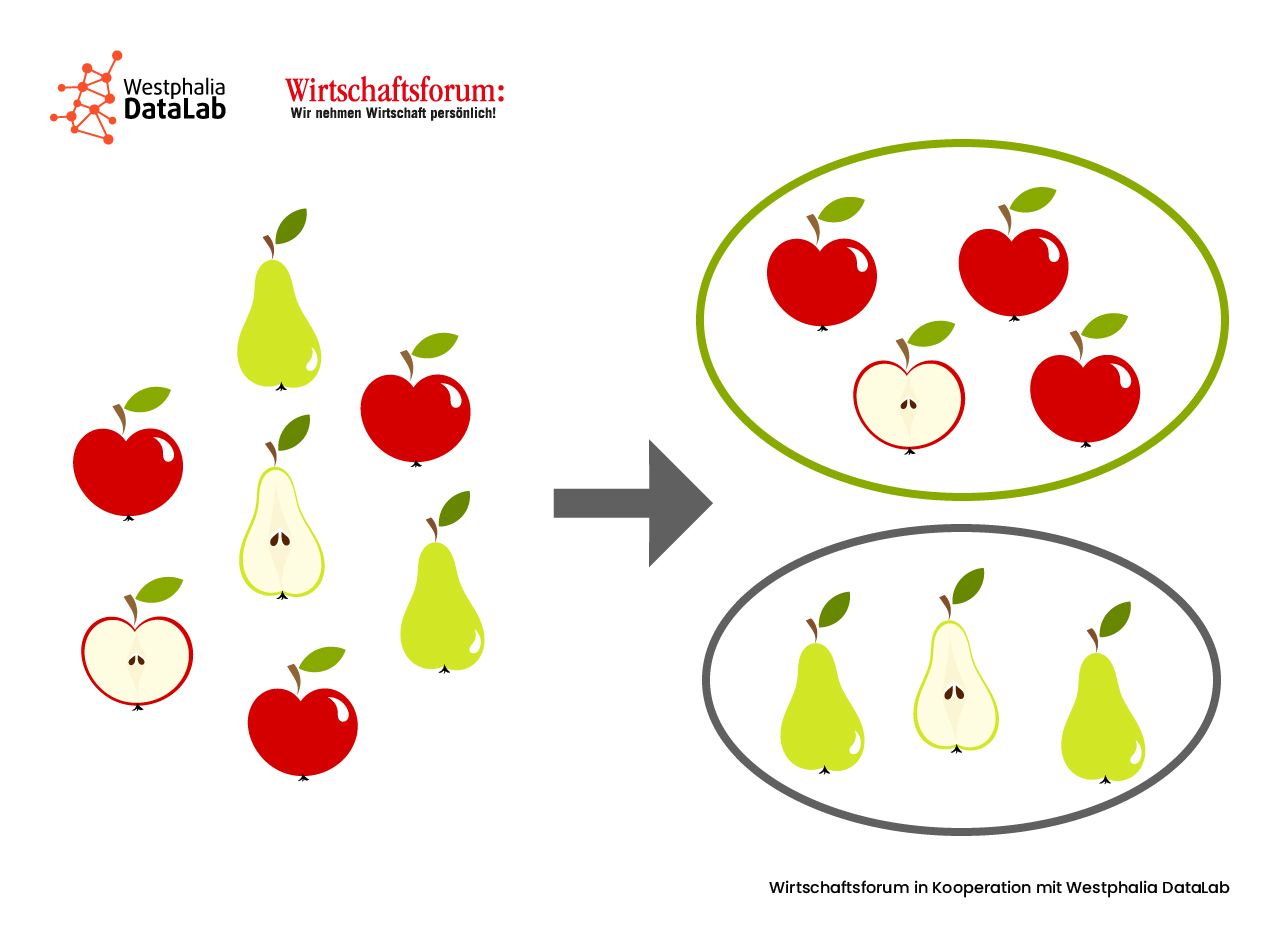
Alternativ, wenn z.B. nicht ausreichend Trainingsdaten vorhanden sind bzw. die Daten vollkommen unbekannt sind, kann auch unüberwacht (unsupervised) gelernt werden. Im System sind jetzt weder Beispieldaten noch Zielkategorien gegeben, der Algorithmus versucht in den vorliegenden Daten Muster zu erkennen und diese in separate Kategorien aufzuteilen. Ein solcher Cluster muss im Anschluss an die Analyse noch benannt werden.
 Lernen")
Eine Mischung aus beiden Methoden stellt das teilüberwachte Lernen dar.
Konkrete Anwendungsbeispiele für ML im (Unternehmens-)Alltag sind breit gefächert und reichen von Bild- und Gesichtserkennung und Verarbeitung natürlicher Sprache über selbstständige Erkennung von SPAM-Mails und relevanten Suchbegriffen für Webseiten bis hin zur Identifikation von Bot vs. natürlicher Personen im Internet und dem automatischen Entdecken von (Kreditkarten-)Betrug.
Auch in der modernen Medizin wird ML erfolgreich eingesetzt: Zum Beispiel analysiert das ML in der Radiologie auf der Suche nach Tumoren verschiedene Bilder. Weiterhin wird es aber auch in der automatischen Diagnostik aus Pathologie-Berichten eingesetzt. Die Verfahren sind bei der Identifikation von Krankheiten deutlich effizienter und erfolgreicher als zuvor eingesetzte manuelle Prozesse.
Im Marketing ist der Einsatz von ML-Technologie nicht mehr weg zu denken: Unternehmer können riesige Datenmengen über vergangene Verkäufe und das Nachfrageverhalten der einzelnen Kunden identifizieren und auf dieser Basis maßgeschneiderte Angebote für jeden Kunden erstellen und anbieten. Je mehr Vergangenheitsdaten über die Käufer vorliegen, desto besser kann vorhergesagt werden, für welche Produkte sich der Kunde in Zukunft interessiert, auf welche Rabattaktionen er anspringen wird und welche Werbeanzeigen ihn ansprechen. Mit Hilfe von hyperrelevanter Werbung heben sich heutzutage Unternehmen aus der riesigen Masse von digitalen Angeboten ab.
Inspiriert von der Struktur des menschlichen Gehirns wurden Neuronale Netze (NN) genutzt, um Daten in ähnlicher Weise zu verarbeiten, wie es die Neuronen in menschlichen Gehirnen können. Um das so gebaute NN jedoch entsprechend zu trainieren, dass neue Informationen korrekt klassifiziert werden können, werden riesige Datenmengen benötigt, die vorab in das System eingespeist werden müssen. Auf diese Weise entstanden Deep Learning (DL)-Modelle. Während sich beim ML die Maschinen bereits selbstständig Zusammenhänge aus riesigen Datenmengen erschließen, trainieren sich die Maschinen beim DL mit Hilfe Neuronaler Netze (NN) und riesiger Datenmengen selbst. Die Leistung und die erzielten Ergebnisse sind nicht im Ansatz mit dem vergleichbar, was Menschen leisten können, wenngleich der Grundgedanke gleich ist. DL-Modelle erkennen Muster und sagen vorher, was z.B. ein bestimmter Kunde aktuell will.

Was sind Künstliche Neuronale Netze?
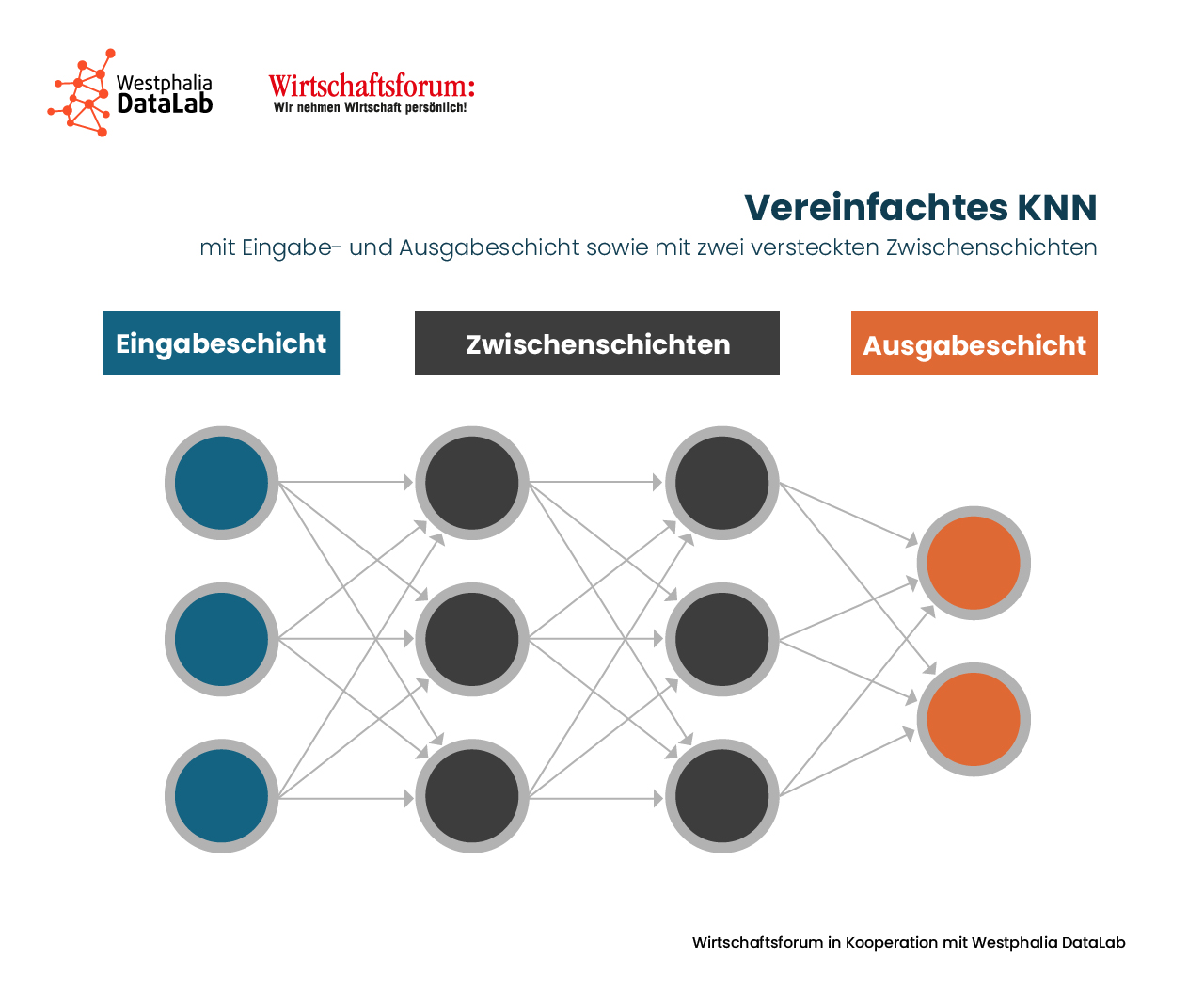
Grundlage für Künstliche Neuronale Netze sind Netze aus künstlichen Neuronen, die als biologisches Vorbild die vernetzten Neuronen im Nervensystem eines Lebewesens haben. Die Neuronen werden im KNN als eine Ansammlung von Informationsverarbeitungseinheiten interpretiert, die schichtweise in der Architektur des Netzes angeordnet sind. Es geht hierbei nicht um die korrekte Nachbildung biologischer neuronaler Netze und Neuronen, sondern um die Abstraktion von Informationsverarbeitung. KNN basieren auf der Vernetzung einzelner Neuronen. Abhängig davon wie die Neuronen auf die einzelnen Schichten verteilt und untereinander verbunden sind, ergibt sich die Topologie des KNN. Üblicherweise werden die Neuronen in hintereinander liegenden Schichten (layers) angeordnet. Dabei sind immer Neuronen zwischen zwei aufeinander folgenden Schichten miteinander verbunden, es besteht aber auch die Möglichkeit, Neuronen innerhalb der gleichen Schicht zu verknüpfen.
Ein KNN wird horizontal dargestellt und von links nach rechts „gelesen“: Neben einer Eingabe- und Ausgabeschicht gibt es eine oder mehrere Zwischenschichten mit trainierbaren Neuronen. Die Eingabeschicht ist der Startpunkt für den Informationsfluss. Die aufgenommenen Daten werden gewichtet an alle Neuronen der nächsten Schicht weiter. Je mehr Zwischenschichten in einem KNN existieren, desto genauer arbeitet das Netz. Hierbei wird auch von „Deep Learning“ gesprochen. Andererseits steigt die benötigte Rechenleistung mit Anzahl der Zwischenschichten, was irgendwann unpraktikabel wird. Die letzte Schicht ist die Ausgabeschicht und enthält das Ergebnis der Informationsverarbeitung durch das gesamte KNN.
Nachdem ein Netz angelegt wurde, folgt die Trainingsphase, in der das Netz lernt. Dabei können u.a. neue Verbindungen entwickelt oder alte gelöscht werden, bestehende Gewichtungen zwischen zwei Neuronen geändert werden, aber auch neue Neuronen gebildet bzw. alte gelöscht werden.
Mit Hilfe der bestehenden Gewichte kann die Intensität des Informationsflusses beschrieben werden. Üblicherweise liegen diese Werte zu Beginn zwischen -1 und 1, während des Trainingsprozesses werden sie aber so angepasst, dass das Endresultat möglichst genau den Anforderungen entspricht.

Der Aufbau eines KNN kann auf viele verschiedene Arten erfolgen:
- Bei einschichtigen Netzen existiert lediglich die Eingabe- und Ausgabeschicht,
- während mehrschichtige Netze auch über ein oder mehrere verdeckte Schichten verfügen.
- Die Feedforward-Eigenschaft eines Netzes sagt aus, dass die Ausgabe der Neuronen nur in Verarbeitungsrichtung erfolgen und nicht zurückgeführt werden kann.
- Bei rekurrenten Netzen existieren zusätzlich auch rückgerichtete Kanten, die dem Netz ein dynamisches Verhalten ermöglichen und es so mit einer Art Gedächtnis ausstatten. Dies wird benötigt, wenn es um sequenzielle Informationsverarbeitung geht, wie bei der Erkennung von Handschriften oder Sprachen oder auch bei der maschinellen Übersetzung.
- Ein Convolutional Neural Network wird im Bereich Bild- oder Audioverarbeitung eingesetzt und besteht mindestens aus fünf Schichten, wobei in jeder Schicht eine immer präziser werdende Mustererkennung durchgeführt wird.
- Die einfachste Form eines KNN sind einlagige Perzeptronen, bei denen nur eine Ein- und Ausgabeschicht sowie entsprechende Gewichtungen existiert.
Die Einsatzbereiche solcher KNN ist sehr vielseitig. Bei komplexen nichtlinearen Problemen mit vielen Eingabedaten und Variablen liefern KNN deutlich bessere Ergebnisse als andere existierende statistischen Ansätze. In der Industrie werden KNN zur Qualitätskontrolle, Sortierung und auch Robotersteuerung eingesetzt. Ein weiterer großer Bereich der KNN bezieht sich auf den Bereich Sprach- und Bilderkennung: Handgeschriebene Zeichen, Ziffern, verbundene Handschrift, Bildersuche und weitere Begriffe wären ohne den Einsatz KNN überhaupt nicht möglich.
Was wurde aus Korrelation, Regression und Co.?
Beim Thema KI und insbesondere KNN fallen viele neue Begriffe, sodass dabei leicht untergeht, dass die dahinterstehende Mathematik tatsächlich klassische Methoden verwendet. Nutzt man das Bild des alten Weins in neuen Schläuchen, dann handelt es sich jetzt um sehr schnell fließenden Wein und extrem große Schläuche, aber der grundsätzliche Ansatz bleibt gleich. Es gibt daher eine Vielzahl bekannter und für den KNN-Einsatz geeigneter Algorithmen, wie etwa Regressionsmethoden, Entscheidungsbäume, sowohl Klassifikations- und Regressionsbäume (CART) als auch Random Forests, Clustering, Support Vector Machines (SVM) und Principal Component Analysis (PCA).
Beim überwachten Lernen bekommt die KI sowohl eine Input- als auch eine Outputvariable und muss den Zusammenhang zwischen beiden herstellen. Bei neuen Daten soll die KI anschließend eine passende Outputvariable ausgeben. Hier wird zwischen Regression und Klassifikation unterschieden, d.h. es wird entweder eine reelle Zahl oder eine Kategorie ausgegeben. In der Regel ist die Klassifizierung, bei der eine Kategorie gewählt wird, die einfachere Variante. Bei einer Regression geht es darum, Merkmale in Abhängigkeit zueinander zu setzen. Beispielsweise soll der Wert eines Grundstückes geschätzt werden. Dafür nimmt man Variablen wie Größe, Wohngegend und Ausrichtung von anderen bereits bewerteten Grundstücken und den dazugehörigen Preis und versucht so einen möglichst realistischen Preis für das unbewertete Grundstück zu bestimmen. Hinter dem Empfehlungssystem bei Online-Verkaufsplattformen steckt ein ähnliches System: Kunden mit ähnlicher Produkthistorie haben ähnliche Interessen. Käufe von ähnlichen Kunden werden nun (z.T. geringfügig angepasst) vorgeschlagen.
Neben der linearen Regression wird auch die logistische Regression in KNN eingesetzt. Hier müssen alle abhängigen Merkmale numerisch sein und es wird eine Trennungslinie ermittelt, die zwei (oder auch mehrere) Klassen voneinander trennt. Schrifterkennung ist ein mögliches Anwendungsbeispiel aus dem Bereich KI, was darauf beruht.
Korrelationen und Regressionen sind eng verwandt: Korrelationen beschreiben Zusammenhänge zwischen Variablen und versuchen nicht den Wert selbst bestmöglich zu schätzen. Sie beschreiben positive sowie negative Zusammenhänge bei bereits existierenden Fällen. Mit Hilfe von KNN können auch Korrelationen oder Regressionen in vorliegenden Daten gefunden werden, die dann anschließend für weitere Klassifizierungs- oder Prognosezwecke genutzt werden können.
Was macht das WDL mit KI und ML?
Das Westphalia DataLab verwendet in den Projekten und Produkten Verfahren der KI und des ML. Durch den Einsatz dieser Methoden ermöglicht das WDL allen Unternehmen eine erfolgreiche Datenanalyse. Voraussetzung ist, dass die Unternehmensdaten vorliegen. Diese müssen dann „nur noch“ mit externen Daten angereichert und durch smarte Analysen automatisiert ausgewertet werden. Erste Erfolge sind durch die unterstützte Auswertung mit künstlicher Intelligenz schneller greifbar, als viele Unternehmer denken. Nicht nur die WDL-Mitarbeiter und Kunden sind von dem Können des westfälischen Unternehmens überzeugt: Im Juli 2019 erhielt das WDL die Auszeichnung vom Center Smart Services der RWTH Aachen. Dort wurden mehr als 300 internationale Anbieter von Machine Learning-Dienstleistungen im industriellen Umfeld im Rahmen einer internationalen Marktstudie untersucht. Das WDL wurde dabei als einziges Start Up und gemeinsam mit vier etablierten, internationalen Industrieunternehmen als „Machine Learning Champion“ ausgezeichnet.

Was erwartet Sie im nächsten Monat?
Wem Lesen oft einfach zu lange dauert, ist nächsten Monat in dieser Rubrik zum Thema „Text Mining“ gut aufgehoben. Zwar müssen Sie den kommenden Blogbeitrag noch selbstständig lesen, aber dafür erhalten Sie Tipps, was durch den Einsatz von Algorithmus-basierten Analyseverfahren zur Entdeckung von Strukturen aus Textdaten in Ihrem Unternehmensalltag in Zukunft verbessert werden kann. Wir zeigen Einsatzmöglichkeiten von Text Mining und klären die Voraussetzung zum Einsatz dieser Algorithmen.
Themenübersicht:
- Anfang Oktober: "Los geht’s: Was erwartet Sie in den nächsten Monaten?"
- Anfang November: "Data Science versus Data Analytics"
- Anfang Dezember: "Big Data oder: Viel hilft viel?!"
- Anfang Januar: "Künstliche Intelligenz versus Machine Learning"
- Anfang Februar: "Text Mining: Weil lesen einfach (zu lange) dauert"
- Anfang März: "Text Mining konkret: Von der Produktentwicklung bis zur Vertriebssteuerung, alles gehorcht aufs Wort"
- Anfang April: "Predictive Analytics: Heute wissen, was morgen passiert"
- Anfang Mai: "Predictive Analytics konkret: Vom Personaleinsatz bis zum Maschinenstillstand, alles ist planbar"



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}